


『일잘러의 무기가 되는 엑셀 대시보드』는 단순히 기능을 알려주는 엑셀 설명서와는 결이 다르다.
이 책은 데이터를 정리하는 방법을 넘어, 데이터를 해석하고 그 안에서 의미 있는 결론을 도출하는 사고 방식으로 시선을 옮기게 만든다. 숫자를 계산하는 사람이 아니라, 숫자를 통해 말할 수 있는 사람이 되도록 이끌어주는 책이었다.
나는 이 책을 바탕으로 엑셀을 공부하고 있다.
하지만 목표는 ‘함수를 많이 아는 사람’이 되는 것이 아니다. 실제 목업 데이터를 만들어 직접 분석해보고, 숫자가 어떻게 흐름을 만들고 판단으로 이어지는지 경험하는 과정에 더 집중하고 있다.
현재 나는 이직을 준비 중이고, 콘텐츠 마케터가 되는 것이 목표다.
그래서 이 책을 읽을 때도 단순히 엑셀을 잘하는 법을 배우겠다는 마음이 아니라,
“이 기술을 마케팅 실무에서 어떻게 활용할 수 있을까?”라는 질문을 품고 읽었다.
그 질문을 가지고 실습을 해보니,
엑셀 공부가 단순한 스킬 업이 아니라 사고 훈련처럼 느껴졌다.
데이터를 구조화하고, 시각화하고, 그 안에서 인사이트를 도출하는 과정이 곧 마케터의 일과 닮아 있었기 때문이다.

이 책을 읽는 시간은 엑셀을 배우는 시간이기도 하지만, 동시에 ‘데이터로 사고하는 연습’을 하는 시간에 가깝다.
그리고 그 점이 이 책을 계속 펼치게 만드는 이유다.
함수에서 끝나지 않는 구조 설계
이 책의 가장 큰 강점은 함수 설명에서 멈추지 않는다는 점이다.
SUM, AVERAGE, IFS 같은 기본 함수부터 시작해 조건부서식, 차트, 피벗테이블 보고서, 대시보드 작성까지 자연스럽게 이어진다. 전체 흐름이 하나의 실무 프로세스처럼 구성되어 있다.
하지만 더 인상적이었던 건 기능을 나열하지 않는다는 점이다.
이 책은 “이 함수를 이렇게 쓰세요”에서 끝나지 않는다. 데이터를 어떻게 가공해야 보고서로 연결되는지, 결국 숫자를 어떻게 전략 단위로 바꿀 수 있는지까지 보여준다.
특히 좋았던 부분은 메뉴 설명 방식이었다.
메뉴바에서 어디를 클릭해야 하는지, 어떤 버튼을 선택해야 하는지까지 화면 캡처와 함께 상세하게 안내해준다.
엑셀을 따라하다 '이건 왜 이렇게 하지?' 라는 궁금증이 들 때면,
어김없이 다음 편에 핵심 Note로 “왜 이 작업이 필요한지”를 짚어주어 단순히 결과만 따라 만드는 느낌이 아니다.
엑셀을 아주 능숙하게 다루는 편은 아니지만,
캡처 화면을 보며 차근차근 따라가다 보니 생각보다 어렵지 않았다.
‘잘 모르겠는데 일단 눌러보는’ 식이 아니라, 이해하면서 클릭하는 경험에 가까웠다.
그래서 실습을 하면서도 막히는 느낌이 적었다. 단순히 “따라 하기”로 완성된 대시보드가 아니라,
“왜 이렇게 설계했는지”를 이해한 상태에서 만들어본 대시보드라는 점이 다르게 느껴졌다.
결국 이 책은 엑셀 기능을 익히게 하는 동시에, 보고서를 설계하는 사고까지 함께 훈련하게 해준다.
그 점이 이 책을 실습용 교재 이상의 책으로 느끼게 만들었다.
데이터 → 시각화 → 판단
대시보드는 예쁜 화면을 만드는 작업이 아니다.
데이터를 한눈에 보이게 정리해, 결국 의사결정을 돕는 도구다.
이 책은 그 본질을 반복해서 강조한다.
그래서 나도 단순히 예제를 따라 하지 않았다.
콘텐츠 업로드 데이터를 가상으로 만들어 시간대별 성과를 엑셀을 활용해 분석해보는 실습을 진행했다.
처음에는 단순 평균 집계부터 시작했다. 결과는 명확했다. 저녁 시간대의 조회수 평균이 가장 높았다.
얼핏 보면 “저녁이 최적 시간이다”라는 결론을 내릴 수 있었다.
하지만 여기서 멈추지 않게 된 것이 이 책의 영향이었다.
조회수 평균을 구하는 데서 끝나는 것이 아니라, 그 평균이 과연 의미 있는지 스스로 묻게 되었다.
그리고 내가 내린 결론으로
- 차트를 어떻게 구성해야 비교가 쉬울지,
- 조건부서식으로 어떤 지점을 강조해야 할지,
- 피벗테이블은 무엇을 요약하기 위한 도구인지 자연스럽게 고하게 되었다.
나는 지금 엑셀을 사용하는 것이 목적이 아니라,
엑셀과 대시보드를 사용해 데이터의 결론을 도출하기 위한 구조를 만들고 있었다.
그러다 데이터 구조에서 한 가지 문제를 발견했다.
게시물 수 구조를 확인해보니 저녁 시간대에 업로드된 콘텐츠는 전부 릴스였다.
그렇다면 이 성과는 ‘저녁 효과’일까, 아니면 ‘릴스 효과’일까. 두 요인을 분리할 수 없는 구조라는 사실을 발견했다.
그래서 시간대별 게시물 수를 따로 집계하고, 평균 대비 몇 배 수준인지 상대지표를 계산해보았다.
그 순간 숫자는 단순한 결과값이 아니라 판단의 기준이 되기 시작했다.
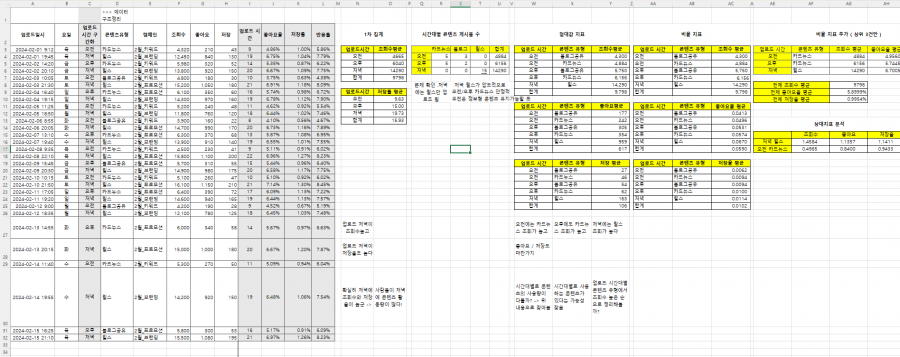
사진으로 캡처한 부분은 함수를 활용해 데이터를 도출해낸 과정이다.
지금은 대시보드를 완성한 단계는 아니지만,
어떤 구조로 시각화하면 더 명확한 판단이 가능할지 고민하고 있다.
그리고 바로 그 고민이 이 책을 읽으며 얻은 가장 큰 변화다.
엑셀을 배우는 것이 아니라 사고를 배우는 책
결국 이 책은 엑셀 기술서가 아니라, 데이터 기반 사고 입문서에 가깝다.
나는 이 책을 통해 함수와 차트, 피벗테이블 같은 엑셀 기능을 배웠다.
하지만 더 크게 남은 것은 기술 자체가 아니라, 숫자를 대하는 태도의 변화였다. 평균을 구하는 데서 멈추지 않고, 그 평균이 무엇을 의미하는지 묻게 되었고, 결과를 보는 데서 끝나지 않고 구조를 확인하려는 습관이 생겼다.
기능을 아는 사람과, 데이터를 근거로 말할 수 있는 사람은 다르다.
이 책은 그 차이를 자연스럽게 경험하게 해줬다.
엑셀을 배우기 위해 펼쳤지만,
결국 나는 데이터를 통해 사고하는 연습을 하고 있었다.
그리고 그 변화가 이 책을 읽은 가장 큰 수확이라고 생각한다.