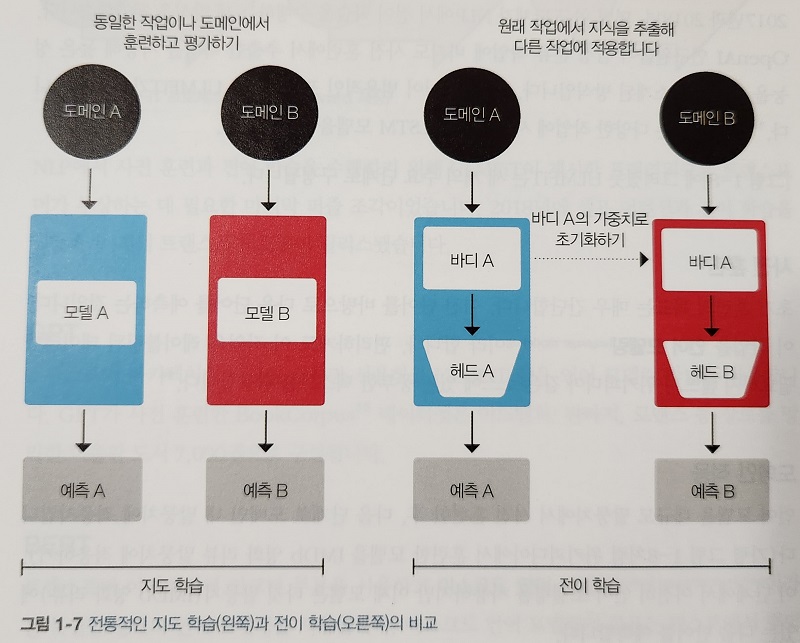
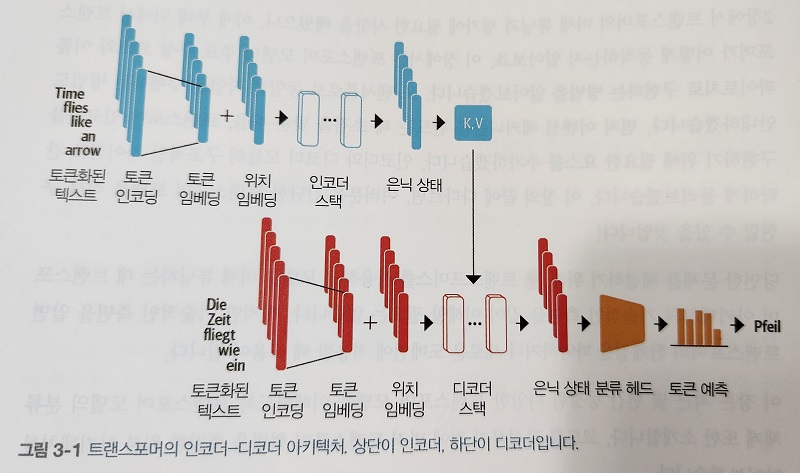
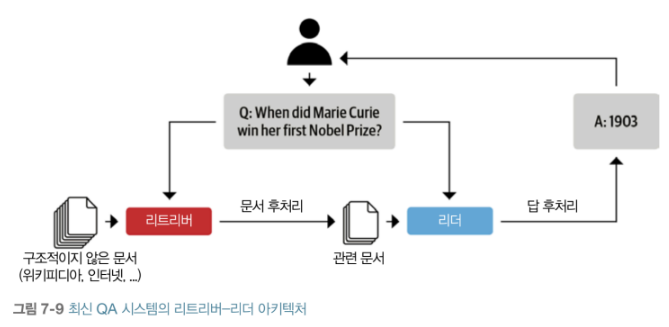
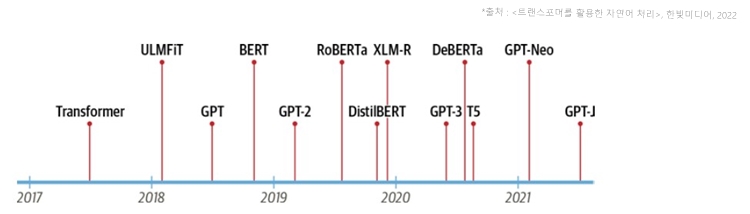
● 코딩의 패러다임이 바뀌고 있다.
- 불과 3~5년 전만 해도 코딩 공부는 이랬다.
- 언어를 하나 정하고 (ex. python)
- 기초 명령어를 여러 개 익힌 후 (ex. print, if ~ else, for 등등)
- 명령어 묶음을 반복해서 사용할 수 있는 함수 작성법과 사용법을 익히고
- 본격적으로 객체를 다루는 클래스 사용법을 배운 다음
- 여러 라이브러리를 사용해 확장성을 넓히는 법을 배웠다.
- 이쯤 배우면 날갯짓을 시작한 아기새처럼 웹에 떠도는 정보를 익히며 스스로 배울 수 있었다.
- 전형적인 상향식(bottom-up) 학습 방식이다.
- 여기에 익숙해져 있다 보니 하향식(top-down) 학습 서적을 봤을 때 매우 당혹스러웠다.
● 발전 속도를 따라잡을 수 없게 되어버렸다.
- 알파고의 여파로 머신러닝에 강제 입문한 2017년에도 별반 다르지 않았다.
- 그런데 이후 월 단위로 새로운 알고리즘이 나와서 따라잡을 수 없게 만들더니
- 이제는 일 단위, 시 단위로 굵직한 결과물들이 터져나온다.
- 상향식 학습으로는 절대로 이 속도를 따라잡을 수 없어서 평생 공부만 하다 자연사할 것 같다.
- 이런 연유로 2~3년 전부터 하향식 학습이 주류를 이루게 되었다.
- 우선 전문가들이 만들어 공개한 라이브러리나 API를 사용해 원하는 목적을 이루고,
- 자세한 내용은 프로그램을 만들면서,
- 또는 일단 만든 후 성능을 개선하면서 어떻게 더 좋게 할까?라는 의문을 던지며 습득하는 식이다.
● Transformer와 Huggingface
- 이 글을 쓰고 있는 시점(2023.3.) 기준으로 ChatGPT의 열풍이 뜨겁다.
- ChatGPT는 2022년 11월 공개된 기술이지만 완성도가 상당히 유사한 GPT-3는 이미 2021년 커뮤니티를 달궜고
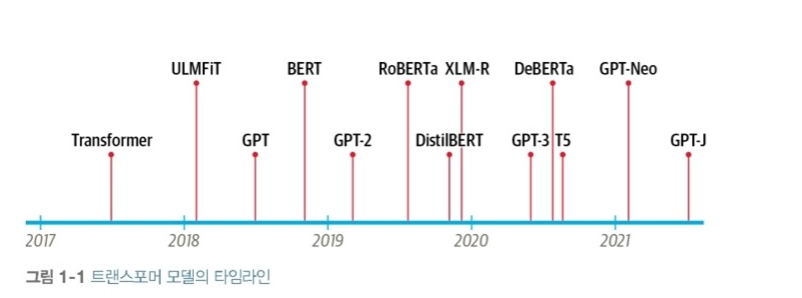
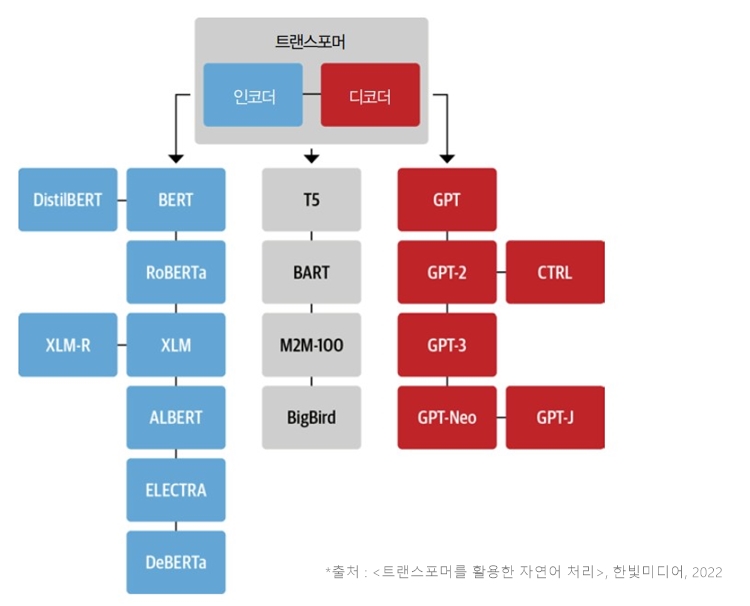
- 이 바닥에는 2017년에 공개된 Transformer라는 딥러닝 모델이 있다.
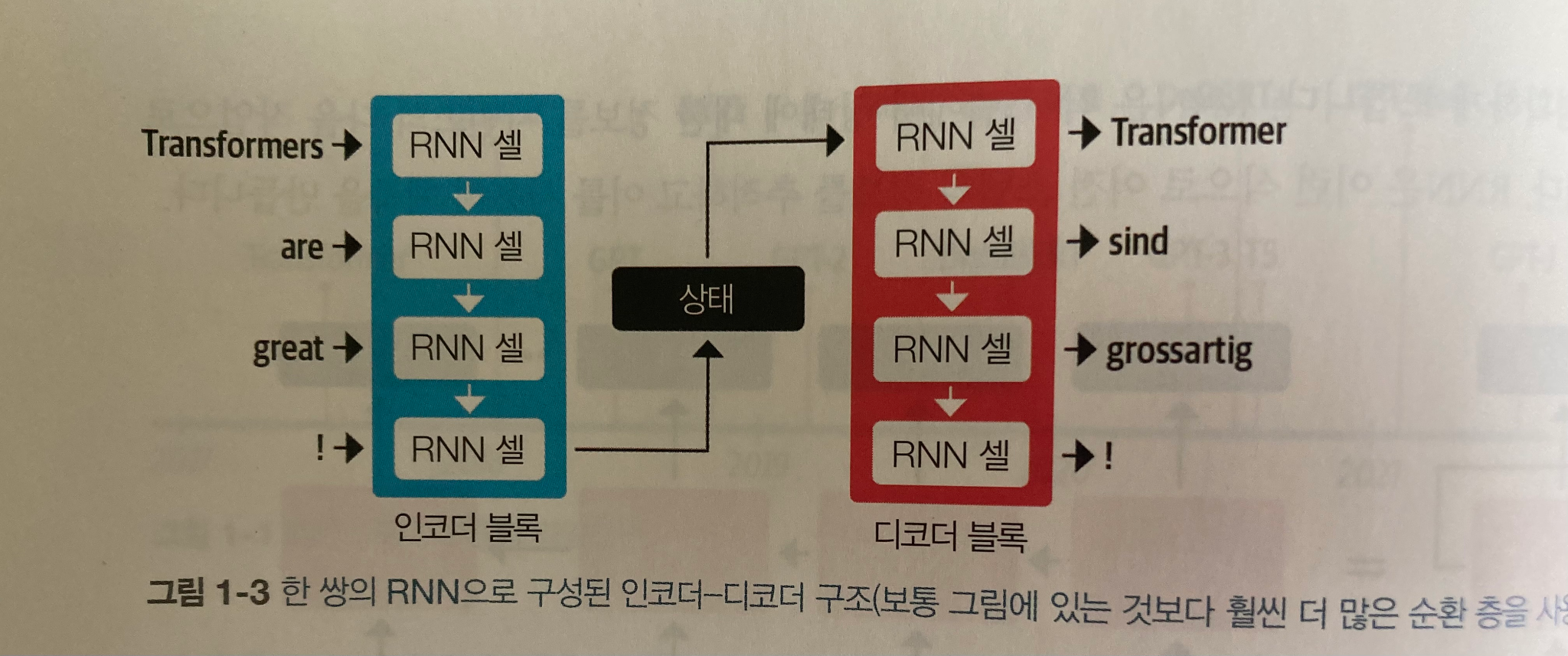
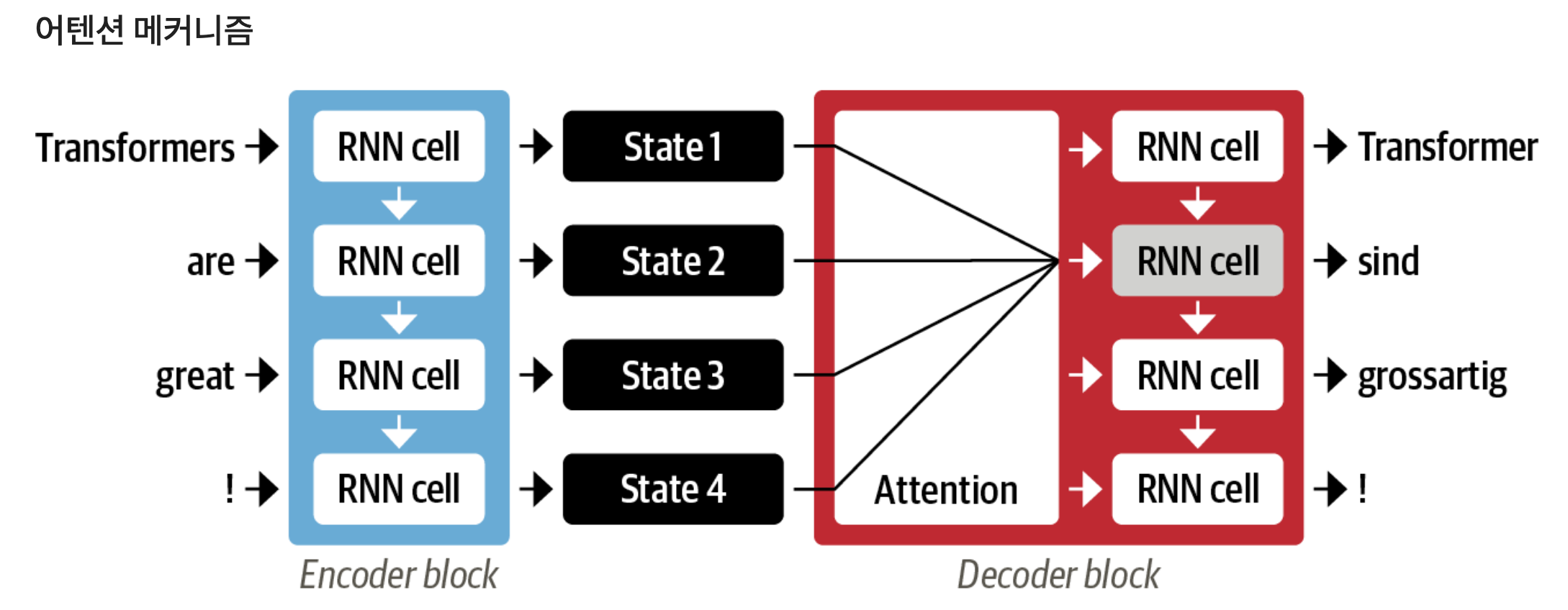
- CNN, RNN을 사용할 때만 해도 라이브러리를 불러 레이어를 한 겹씩 쌓아 모델을 만들었는데
- ResNet 무렵부터는 직접 만드는 것보다 사전학습된(pretrained) 모델을 받아 쓰는 것이 당연해졌다.
- 이와 동시에 내 컴퓨터가 아니라 클라우드에 접속해서 머신 러닝 모델을 실행하는 것이 당연해졌다.
- 학습을 위해 작성하는 간단한 코드마저도 내 컴퓨터가 아닌 Google Colab에서 실행하게 되었으며
- 처음에는 낯설었지만 이제는 모두가 사전학습모델과 클라우드 컴퓨팅에 익숙해졌다.
- 그리고 언어 모델의 중심에 Transformer, 모델 및 데이터셋 공유 플랫폼의 중심에 Huggingface가 있다.
- 기존에 내가 살아온 분야에서는 상상할 수 없는 개방과 공유를 통해 발전을 가속시키는 구심점들이다.
- 널리 쓰이는 github이 코드 공유의 중심이라면 Huggingface는 응용성이 한 단계 더 높다고 볼 수 있다.
- 딥러닝 입문자로서 Huggingface가 낯설게 느껴진다면, 모델 구축 방법보다 사용법을 먼저 익혀야 할지도 모른다.
● 트랜스포머를 이용한 자연어처리
- 자연어처리는 결코 만만한 분야가 아니다.
- 먼저 평생 글자로 익혀온 대상을 갑자기 벡터로 바라봐야 한다는 점에서 뇌가 꼬이는 느낌이 들고
- 학창시절에 잠깐 배우고 쓸 일이 없던 형태소, 자소 같은 용어들이 마구 등장한다.
- 영어로 조금 실습을 하다가 한글로 하려면 조사는 어떻게 되는거지? 같은 의문들이 꼬리를 문다.
- 이 책도 최근의 같이 일단 간단한 예제를 한번 실행해본 후 세부적인 기능을 짚는다.
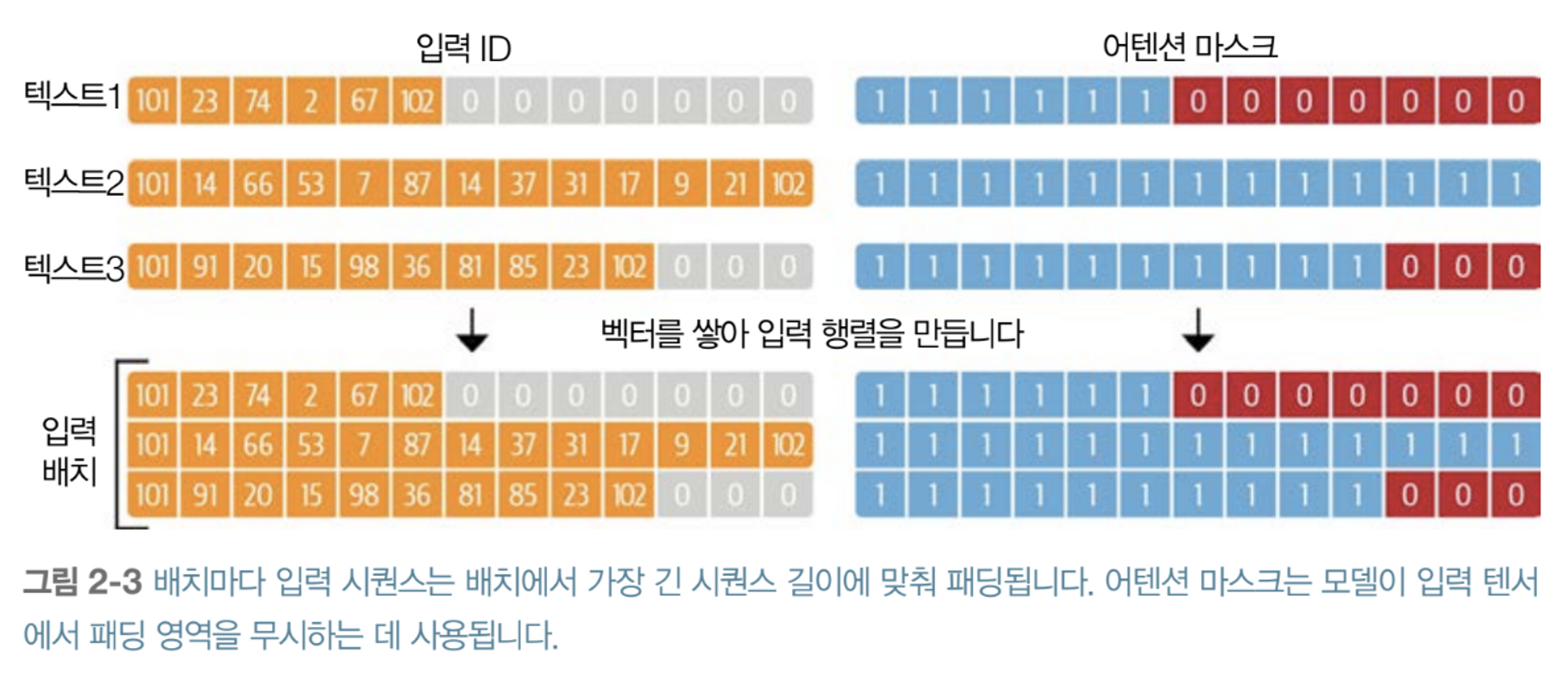
- 문자 토큰화와 단어 토큰화를 예제와 함께 실습함으로써 단어가 숫자로 변환하며 벡터 변환의 감을 잡고
- 트랜스포머를 미세 조정해서 나에게 맞는 모델로 만들어가는 경험을 한다.
- 이후 다중 언어 처리, 텍스트 생성, 요약, 질문 답변을 통해 다양한 기능을 경험하고
- 마지막 단계로 효율성을 높이는 과정과 레이블 부족을 해결하는 예제, 그리고 데이터 수집 예제를 통해 나만의 서비스를 만들 준비를 탄탄히 한다.
● ChatGPT 시대의 코딩
- 트랜스포머 모델이 불러온 GPT-3, 그리고 챗봇의 옷을 입은 ChatGPT는 코딩을 못하는 일반인들에게도 스며들고 있다.
- 예전같이 목적도 모르고 외력에 의해서, 또는 흐름에 쓸려서 코딩을 배우는 바람직하지 못한 동기보다
- 당장 스스 겪고 있는 문제를 해결하기 위해 명확한 목적을 가지고 코딩에 입문하는 이들이 많아질 것 같다.
- 이 책에서는 트랜스포머를 다루고 있지만, 책에서 전달하고자 하는 그림은 더 큰 것으로 보인다.
- 트랜스포머가 아니더라도 허깅페이스를 통해 머신 러닝 모델을 공유하며
- 서로의 그림에 덧칠을 하면서 점점 더 멋진 모습을 그려나갈 수 있는 역량을 갖는 것이 이 책의 본 목적으로 생각된다.
- 앞으로 어떤 것들이 더 나올지 궁금하고 기대되는 요즘이다.