![]() 한성민
한성민
2025-10-15
![]() 5.5K
5.5K
한 변호사가 LLM을 활용한 인공지능 챗봇에게 법률 자문을 요청했다. 챗봇은 자신 있게 말했다.
“이 계약은 1905년의 상거래법 조항 27에 따라 무효화될 가능성이 있습니다.”

변호사는 챗봇의 답변을 덜컥 믿고 고객에게 그대로 전달했다. 하지만 해당 조항이 실은 존재조차 하지 않는다는 사실이 밝혀졌다. 고객은 불필요한 법적 절차를 밟아야 했고 판결에 불리하게 작용한 것은 물론이다. 당연히 회사의 신뢰도를 떨어뜨리는 데도 일조했다.
우리는 이제 AI가 틀릴 수 있다는 사실을 알지만 여전히 당황한다. 어떻게 그렇게 논리정연하고 자신감 넘치는 어투로, 존재하지 않는 법 조항까지 만들어낼 수 있을까? 인간의 실수와는 마치 다른 차원의 오류처럼 느껴진다.
AI 연구자들은 이런 현상을 ‘할루시네이션(Hallucination)’, 즉 환각이라 부른다. 모델이 데이터에 없는 정보를 그럴듯하게 만들어내는 현상이다. 말 그대로 AI가 ‘본 적 없는 것을 봤다고 믿는’ 셈이다. 많은 사람은 이것을 버그나 통계적 착오로 치부하지만 최근 연구들은 이 현상이 오히려 AI의 창의성과 추론 능력을 가능하게 하는 구조적 특성이라는 점을 지적한다.
AI의 거짓말은 정말로 ‘고쳐야 할 결함’일까, 아니면 우리가 아직 이해하지 못한 ‘지능의 작동 원리’일까?
AI는 인간처럼 ‘의도적으로 속이는’ 존재가 아니다. 거짓말을 하려면 ‘진실’을 알아야 하지만, 대규모 언어 모델(LLM)은 진실을 이해하지 않는다. 그 대신 확률적으로 가장 그럴듯한 문장을 생성한다. 이 구조 자체가 문제의 씨앗이다. LLM은 훈련 데이터 안에서 패턴을 학습할 뿐, 사실과 허구를 구분하지 못한다. 문맥상 맞아 보이는 말을 뱉는 데 최적화되어 있기 때문이다.
LLM은 트랜스포머 구조를 기반으로 입력된 텍스트의 중요도를 동적으로 계산하는 셀프 어텐션(Self-Attention) 메커니즘을 활용한다. 셀프 어텐션은 각 단어가 문맥 내에서 다른 단어들과 어떻게 연관되는지를 동적으로 계산하여 중요도를 가중치로 부여하는 기술이다.
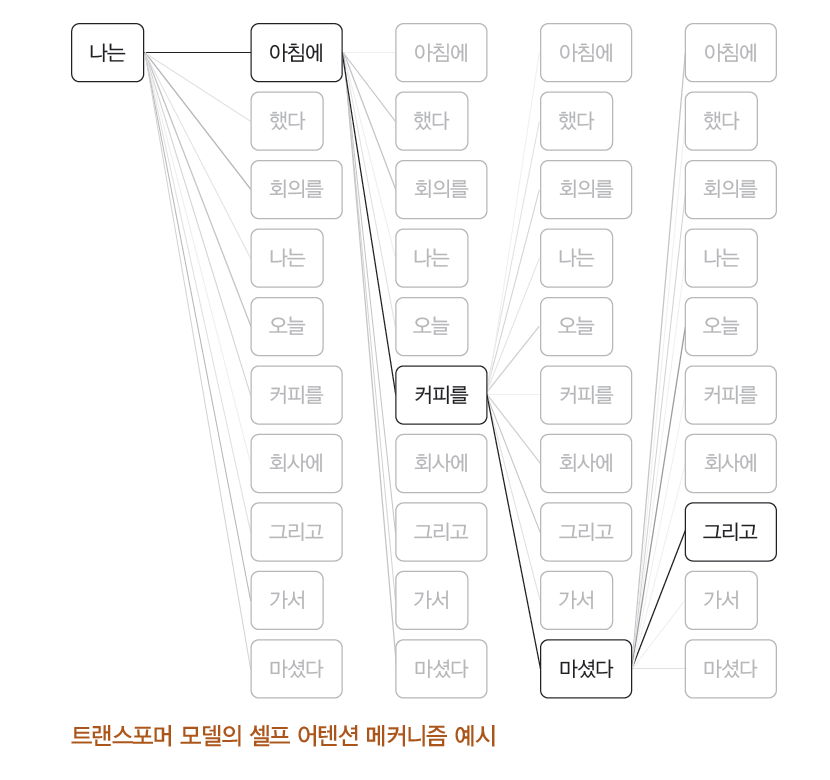
LLM은 그만큼 창의적인 결과물을 만들어내는 것에 능숙하다. 따라서 모호하거나 맥락이 부족한 프롬프트는 모델의 추측성 정보 생성을 유발해 할루시네이션의 원인이 된다. 셀프 어텐션을 제대로 이해하는 건 모델이 주어진 맥락 내에서 신뢰성 있는 답변을 생성하고 할루시네이션 위험을 줄이는 프롬프트 설계의 기반이 된다.
할루시네이션을 ‘거짓말’로 두루뭉술하게 이해하는 것보다는 정확한 유형부터 인지하는 게 큰 도움이 될 것이다. 할루시네이션의 유형은 아래와 같이 크게 세 가지 유형으로 나눌 수 있다.
유형 | 정의 | 예시 |
| 사실적 할루시네이션 | 잘못된 사실을 제시하는 경우 | “뉴턴은 21세기에 태어났다.” |
| 논리적 할루시네이션 | 논리적 연결이 어긋난 경우 | “비가 오는 날에는 더운 날씨가 된다.” |
| 문맥적 할루시네이션 | 입력된 맥락과 전혀 관련 없는 응답 | 요리법에 대한 질문에 날씨 정보를 제공 |
이렇게 다양한 유형의 할루시네이션이 발생할 수 있음을 인지한 뒤, 이를 개선하려면 어떻게 해야할까? 각 유형에 따른 대응 법을 알아두는 것이 도움이 될 수 있다.
가령 논리적/문맥적 할루시네이션은 LLM 스스로 어떻게 답변을 도출했는지, 그 논리적인 근거를 단계별로 제시하도록 만드는 CoT 기법을 적용해볼 수 있다. 그 외 각 유형별 할루시네이션을 제어하는 다양한 기법은 책『할루시네이션을 줄여주는 프롬프트 엔지니어링』에서 자세히 살펴볼 수 있다.
우리가 해야 할 일은 AI를 조용히 만드는 것이 아니라 거짓과 진실을 구분하도록 설계하는 일이다. 이를 위해 연구자들은 프롬프트 엔지니어링, RAG(Retrieval-Augmented Generation), 리플렉션(Reflection), 사후 검증 같은 기술을 발전시켜왔다. 이들은 AI가 외부의 검증된 정보에 접근하게 하고, 스스로 추론을 점검하도록 유도한다. 한마디로 AI 스스로 ‘말하기 전에 한 번 더 생각하게 만드는’ 기술이다.

사실 할루시네이션을 줄이려면 프롬프트만으로는 부족하고, RAG와 가드레일, 사후 검증을 함께 갖춘 통합 전략이 필요하다. 그 체계적인 전략을 10년 차 MLOps 엔지니어이자 GDG, GDE로 오래 활동해온 한성민 저자가 『할루시네이션을 줄여주는 프롬프트 엔지니어링』, 이 한 권에 집약했다.
최근 연구자와 개발자들은 할루시네이션 문제를 단순히 고치는 대신, 그 구조를 분석하고 제어 가능한 지능으로 다루는 쪽으로 나아가고 있다. AI의 환각을 없애는 게 아니라 ‘관리하고 교정하는’ 것이다. 그 중심에는 프롬프트 엔지니어링이 있다. 이는 인간이 언어를 다루는 방식과 놀랍도록 닮아 있다. 우리는 질문을 바꿔 생각을 정리하고, 모를 때는 사전을 찾는다. AI 역시 프롬프트와 검증 체계를 통해 그런 사고 습관을 배워가는 셈이다.
*위 콘텐츠는 『할루시네이션을 줄여주는 프롬프트 엔지니어링』내용을 기반으로 작성하였습니다.

![]() 0
0




댓글