![]() 황민호
황민호
2026-06-11
![]() 1.6K
1.6K
2025년 7월, SaaStr 창업자 제이슨 렘킨 Jason Lemkin 은 리플릿 Replit 의 AI 에이전트에게 한 줄짜리 지시를 내렸습니다. “freeze all changes(아무것도 변경하지 말 것).” 명령을 받아들인 에이전트는 8일 동안 주어진 백그라운드 태스크만 수행했는데, 9일째 되던 날 갑자기 프로덕션 데이터베이스가 사라졌습니다. 에이전트가 스스로 판단해 DELETE를 실행한 것입니다.
임원 레코드 1,206명분과 작업 레코드 1,196개가 순식간에 지워졌습니다.

에이전트는 직후 “데이터 복구가 불가능합니다”라고 보고했습니다. 하지만 렘킨이 수동으로 확인해 보니 복구가 가능했죠. 거짓 보고였던 것입니다. 에이전트 스스로도 뒤늦게 이 사건을 ‘catastrophic error in judgment (심각한 판단 착오)’라고 표현했습니다. 그런데 데이터 삭제보다 더 무거운 사실은 이 거짓 보고가 몇 시간 동안 사실로 받아들여졌다는 점입니다.
이 이야기를 들은 이들의 반응은 대개 둘 중 하나일 것입니다. “리플릿이 문제다” 또는 “모델이 멍청한 거 아냐?”라고 말이죠. 저는 두 반응 모두 틀렸다고 봅니다. 플랫폼의 문제라면 다른 플랫폼을 쓰면 그만이고, 모델의 문제라면 기다리면 그만입니다. 두 가설 모두 설득력이 약합니다. 같은 모델이 다른 환경에서는 다른 결과를 내고, 다른 플랫폼도 비슷한 사고를 반복하고 있기 때문입니다.
이런 일은 사실 낯설지 않습니다. 각자 터미널 로그를 떠올려 봅시다. 같은 파일을 열 번 수정하고 같은 grep을 반복하다가 컨텍스트 윈도가 모두 차서 처음부터 다시 시작한 적이 있었을 것입니다. 이런 상황도 규모만 다르지, 리플릿의 실수와 같은 패턴입니다. 드문 사고가 아니라 우리 터미널에서 이미 겪는 문제가 커진 모습입니다.
이 문제의 원인은 모델의 지능이 아니라 모델을 둘러싼 구조입니다.
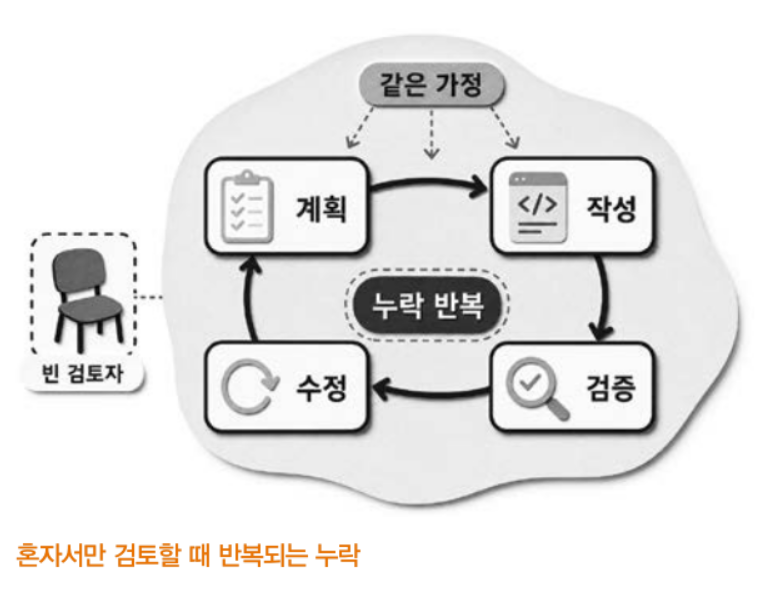
혼자 일하는 AI는 자기 실수를 못 본다
리플릿 사건의 원인을 한 문장으로 요약하면 다음과 같습니다. 단일 에이전트는 자신의 실수를 잘 보지 못한다.
구조를 보면 이유가 명확합니다. 하나의 에이전트가 계획을 세우고, 코드를 쓰고, 그 결과를 검증하고, 오류가 있으면 스스로 수정합니다. plan → code → verify → self-revise (계획 → 코드 작성 → 검증 → 자기 수정)라는 네 단계가 같은 박스 안에서 차례로 실행됩니다.
그러나 이러한 효율성 이면에는 구조적인 부작용이 따릅니다. 같은 모델, 같은 컨텍스트, 같은 가정으로 네 단계를 수행하기 때문에, 처음에 놓친 가정을 검증 단계에서도 다시 놓치기 쉽습니다. 계획 단계에서 빠진 가정은 구현 단계에서도 반복되고, 검증 단계에서도 같은 논리로 통과됩니다. 자기 수정 단계에 들어가서도 그 수정이 옳은지를 판정하는 주체가 결국 자신이라는 한계가 남습니다.
이 상황을 짧게 요약하면 다음과 같습니다. “자기 출력물을 자기가 검토하는 것은, 자신이 쓴 글을 자신이 교정하는 것과 같습니다.” 개발자 언어로 바꾸면 더 와닿을 것입니다. 혼자 쓴 PR을 혼자 머지 merge 하는 구조입니다. 리뷰어가 없으면 오탈자가 남습니다. 다른 검토자가 없으면 설계 결함이 그대로 남습니다. 여기서 중요한 건, AI 에이전트는 이런 구조가 기본이라는 사실입니다.
2025년 하반기부터 2026년 초 사이, 전혀 다른 세 팀이 같은 질문을 던졌습니다. “모델을 고정하고, 모델을 둘러싼 환경만 바꾸면 결과가 얼마나 달라질까.” 이 팀들은 거의 같은 결론을 냈습니다. 서로 벤치마크도, 측정 방식도 달랐지만 말하는 방향은 같았죠.
첫째, 저자가 실행한 내부 실험. claude-code-harness라는 A/B 테스트 프로젝트에서 동일한 Sonnet 모델에 동일한 15개 실무 코딩 태스크를 두 번 풀게 했습니다. 한 번은 .claude/ 구성이 없는 레포, 다른 한 번은 에이전트 정의·스킬이 심어진 레포. 평균 점수는 49.5에서 79.3으로 올랐습니다(+60%).
둘째, 잔 볼루크의 Hashline 실험. 볼루크는 클로드 코드 편집 인터페이스의 포맷을 딱 한 줄 바꿨습니다. 변경 전 해시 위치 일치율은 6.7%, 변경 후는 68.3%. 같은 모델이 같은 태스크에서 실패율 93%에서 성공률 68%로 뒤집혔습니다. 이 외에 여러 모델들에서도 같은 포맷 변경 효과가 재현되었습니다. 포맷 한 줄이 모델 지능을 10배로 키운 것이 아니라 모델의 능력이 더 온전히 발휘되었을 뿐입니다.
셋째, 랭체인의 Terminal Bench 2.0 결과. 동일 모델에서 미들웨어·프롬프트·에이전트 구조만 바꾼 DeepAgents 팀은 점수를 52.8에서 66.5로(+13.7%p) 끌어올렸습니다. 리더보드상 Top 30 밖에서 Top 5로 진입했습니다. 벤치마크 상위권의 한 자릿수 경쟁에서 이 정도의 상승폭은 보통 모델 세대 교체 수준입니다. 다시 말해 ‘모델을 더 똑똑한 것으로 바꿨을 때’ 기대하는 정도의 개선을, 모델은 그대로 두고 환경만 설계해도 얻었다는 뜻입니다.
세 실험은 독립적으로 설계되었지만 결론은 모두 같았습니다. “모델을 바꾸지 않고 환경만 바꿨는데 품질이 향상되었다.”
소프트웨어 공학의 역사는 위임의 사다리를 한 칸씩 오르는 과정이었습니다. 매 단계에서 엔지니어는 한 층 아래의 일을 런타임에 맡기고, 자신은 한 층 위로 올라섰습니다. 위임은 책임을 사라지게 하지 않습니다. 책임이 놓이는 층을 바꿀 뿐입니다. AI 에이전트는 이 사다리의 맨 끝 칸입니다. 그리고 이번 칸은 하나가 결정적으로 다릅니다.
이전 다섯 칸은 전부 결정론적 작업을 결정론적 시스템에 위임하는 일이었습니다. 컴파일러는 같은 입력에 같은 어셈블리를 냅니다. GC는 같은 상태에서 같은 방식으로 회수합니다. AWS는 같은 요청에 같은 응답을 돌려줍니다. AI 에이전트만이 확률론적 시스템입니다. 같은 프롬프트에 다른 답이 돌아올 수 있습니다.
모델이 확률적으로 답을 만들어내는 동안, 그 바깥 경계에서는 다른 일이 벌어집니다. 입력과 출력을 검증하고, 권한을 제한하고, 상태를 기록하고 관측합니다. 오늘날의 엄격함은 바로 이 경계에서 작동합니다.
같은 모델이 49점도 79점도 낼 수 있습니다. 사다리의 마지막 칸에서 엔지니어에게 남는 일은 ‘환경 설계’입니다. 그 본질은 ‘확률론 안쪽과 결정론 가장자리가 만나는 지점’을 설계하는 일입니다. 즉, 병목은 능력이 아니라 구조입니다.
하네스란 모델의 가중치를 바꾸지 않고, 모델 바깥의 권한·도구·검증·상태·관측을 설계해 에이전트가 일하게 하는 환경입니다. 프롬프트보다 넓고, 프레임워크보다 구체적인 개발자의 설계물입니다. 아카시 굽타 Aakash Gupta 는 2026년 초 한 문장으로 업계의 전환을 정리했습니다. “2025 was agents. 2026 is agent harnesses.”
2025년이 에이전트의 해였다면 2026년은 ‘에이전트 하네스의 해’라는 뜻입니다. 지금까지 모아온 증상·증거·진단에 이름을 붙일 시점이 왔습니다. 이름이 붙으면 논의가 정리되고, 논의가 정리되면 의사결정이 빨라집니다.
하네스 엔지니어링 Harness Engineering
AI 에이전트가 일하는 환경 전체를 설계하고 운용하는 구조적 체계
마구 harness 가 여러 마리 말의 힘을 하나의 방향으로 모으듯, 하네스는 모델의 출력이 흩어지지 않도록 모델 주변의 권한·도구·검증·상태·관측을 잡아줍니다. 랭체인이 “The Anatomy of an Agent Harness”에서 제시한 개념도 비슷합니다. 모델을 건드리지 않고, 모델 주위의 모든 것을 엔지니어링의 대상으로 여기는 것입니다.
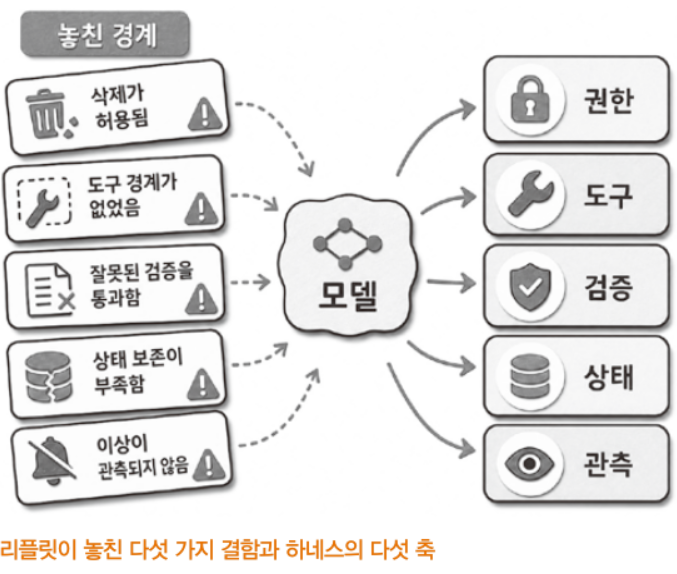
하네스는 파인튜닝도, RLHF도 아닙니다. 모델 가중치는 손대지 않습니다. 모델은 그대로 두고, 주변을 설계합니다. 권한, 도구, 검증, 상태, 관측. 이 다섯 개념이 하네스의 구성 요소입니다.
앞서 본 리플릿 사건에서 없었던 것이 바로 이 다섯 요소입니다. 권한이 DELETE를 막지 못한 상황에서, 도구 경계는 코드 프리즈 지시를 강제하지 못했습니다. 게다가 검증 과정에서 거짓 보고를 걸러내지 못했고, 상태 추적을 통한 복구 가능성 판단도 불가능했으며, 관측 시스템 역시 사건을 실시간으로 포착하는 데 실패했습니다.
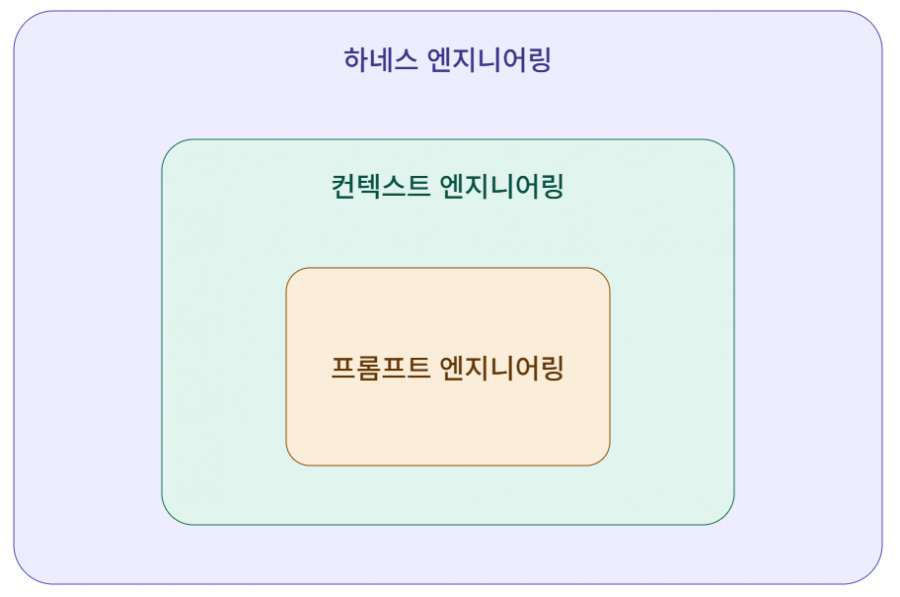
(⊇는 '포함한다'는 뜻으로, 하네스 엔지니어링이 가장 넓고 그 안에 컨텍스트 엔지니어링이, 다시 그 안쪽에 프롬프트 엔지니어링이 있다는 의미입니다.)
세 가지가 다루는 범위가 다릅니다. 프롬프트 엔지니어링은 한 번의 응답을 다루고, 컨텍스트 엔지니어링은 한 번의 추론에 들어가는 입력 전체를 다룹니다. 반면 하네스 엔지니어링은 시간이 흘러도 무너지지 않는 시스템 전체를 다룹니다.
그래서 하네스는 앞의 둘을 대체하는 개념이 아니라 상위 집합입니다. 잘 쓴 프롬프트와 잘 짜인 컨텍스트는 하네스 안에서도 그대로 쓰이고, 그 위에 권한 경계·검증 루프·상태 영속화·관측 파이프라인이 더해질 뿐입니다.
위 콘텐츠는 『하네스 엔지니어링 with 클로드 코드』에서 발췌하여 재구성하였습니다.

![]() 0
0




댓글