2년 전 이 책의 1판을 처음 접했을 때 큰 감동을 받았다. 다만 딱 한 가지 아쉬웠던 점은, 당시 Spark가 2.x 버전을 발표하고 API의 패러다임을 RDD에서 DataFrame으로 바꿔가고 있었는데 반해 1판은 주로 RDD API를 사용했다는 점이었다. 이번에 새로 출간된 2판은 불가피한 경우를 제외하고는 모든 예제를 DataFrame 기반으로 변경하였는데, 1판과 2판을 모두 읽은 입장에서는 사실상 다른 책이라고 느껴질 정도로 또다른 감동을 받았다. 그 감동을 공유하고자 한다.
이 책에는 엔지니어링 관점에서 Spark 클러스터를 어떻게 구성하고 데이터 처리 성능을 어떻게 높일 수 있는지에 대한 내용은 거의 없다. (이런 내용은 창시자들이 직접 쓴 Spark: The Definitive Guide를 참조하는 것이 좋겠다.)
그보다는 오로지 데이터 분석가의 관점에서 Spark를 이용해서 가치를 만들어내는 과정을 아주 소상히 담아냈다. 어찌나 소상한지 마치 ‘어느 데이터 분석가의 하루'라는 에세이처럼 느껴질 정도다. 데이터를 적합한 포맷으로 불러와서 기본 통계를 살펴보며 이상 데이터를 제거하고, 분석에 편리한 형태로 가공한 뒤 해결하고자 하는 문제에 맞는 모델을 만들고 평가하고, 다시 개선해서 평가하고, 또 다시 개선해서 평가하고, 그리고 마지막으로 다시 개선해서 평가하고… 얼마나 현실적인지 한 챕터에서는, 수십페이지 분량의 코드로 데이터를 이리저리 구워삶아 모델을 만들어 내고서는 아래와 같이 마무리한다. 얼마나 현실적인가? 데이터 분석가가 어떤 일을 하는지 작은 단면을 들여다보고 싶다면 이 책을 추천한다. 물론 모든 것이 가능하다고 말할 수 있겠지만, 이를 직접 보여주기는 쉽지 않다. 이 책에서는 음악 추천, 식생 분포 예측, 네트워크 이상 탐지, 위키백과 숨은 의미 분석, 의학 논문 인용 그래프 분석, 택시 운행 데이터 분석, 금융 리스크 추정, 유전체학 데이터 분석, 신경 영상 데이터 분석 이라는 9가지 주제로 시연을 한다. 최대한 Spark의 다재다능함을 보여주기 위해 기본 DataFrame API를 이용해 평균, 표준편차를 구하고, 카이 제곱 통계량을 계산해서 요소간의 독립 사건인지를 확인한다. 또 교차 테이블을 만들어 False Positive와 False Negative의 수를 확인하고 AUC를 계산한다. 나아가서 Spark MLlib를 이용해 Matrix Factorization으로 추천 모델을 만들고, 회귀분석도 시행한다. Decision Tree와 Random Forest 기법도 손쉽게 수행한다. Spark GraphX를 이용해서 네트워크 평균 군집계수를 계산한다.
Spark가 JVM 기반으로 작동한다는 사실을 이용해 Scala, Java 생태계에 만들어져 있는 라이브러리도 잘 가져다 사용한다. Apache Commons Math 라이브러리를 이용해 몬테카를로 시뮬레이션과 회귀분석을 시행한다. GeoJSON 관련 라이브러리를 가져다 지리정보 분석도 한다.
대충 들춰보며 찾아본게 이정도이고, 지식 부족으로 전혀 이해하지 못한 여러가지 개념들을 Spark를 이용해 구현하는 과정을 책을 통해 생생하게 목격할 수 있다. 몇몇 주제들은 예제 데이터의 크기가 워낙 커서 로컬 환경에서 따라해보기가 쉽지 않았다. (아예 실패하기도 했다.) 또 금융 데이터는 아예 구할수가 없게 되어 깃헙에 따로 포함을 시켜줬지만 책과는 다른 형태의 데이터라 별도의 주의가 필요하다.
그리고 모든 예제가 spark-shell 기반으로 작업한다는 것을 전제로 하는데 이 많은 코드를 정말 shell 기반으로 작업한게 맞는지 의심이 든다. 몇 번 순서를 실수해서 처음부터 다시 작업해야 하는 상황을 겪었다면 분명 웹에서 Notebook 기반으로 쉽게 작업할 수 있는 Apache Zeppelin을 소개해줬을 것이다.
그래서 어렵게 클러스터 환경을 구해서 Apache Zeppelin을 기반으로 실습을 진행했는데, 뒤로 갈수록 클러스터를 직접 수정할 수 없는 상황에서는 실습을 위한 의존성 관리가 쉽지 않았다. 그리고 3판이 나온다면 Spark 기반의 Deep Learning 분석 내용을 꼭 포함해줬으면 한다. 유난히 생소한 통계 개념이 많이등장해서 정독하는데 오래 걸렸지만 즐거운 시간이었다. 학습 자료가 인터넷에 넘쳐나는 세상에서, 이렇게 양질의 내용이 잘 구조화된 묶음이 책의 존재 이유가 되었으면 한다.
데이터 분석가는 어떤 일을 하는가?
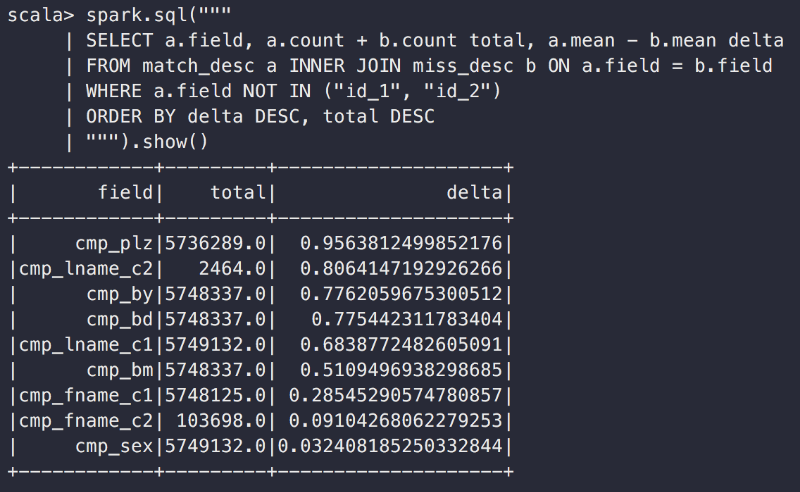
우리 모델은 관측된 현실에는 잘 맞지 않는다. 더 개선해야 할 필요가 있어 보인다.
Spark로는 어떤 분석이 가능한가?
그럼 아쉬운 점은?