이 책은 python 뿐만 아니라 javascript로 동일 예제를 두번 설명해준다. 또한 LLM을 편하게 사용하기 위한 랭체인 프레임워크를 너무 쉽고, 친절하게 가르쳐준다. 바쁜 와중에도 이 책은 내가 앉아서 시간을 들여 읽어도 아깝지 않다는 생각이 들었던 몇 안되는 책이였다.
전자책은 웹뷰어와 한빛+ 앱에서
열람할 수 있으며, PDF 다운로드는 지원되지 않습니다.
대여 가능
전자책
종이책
LLM 엔지니어링의 모든 것을 망라한 실전 가이드
이 책은 프로덕션 수준의 LLM 애플리케이션을 개발하고 배포하는 데 필요한 엔지니어링 방법들을 상세히 안내한다. LLM 라이프사이클을 체계적으로 살펴보며, 데이터 엔지니어링부터 지도 학습 파인튜닝, 모델 평가, 추론 최적화, RAG 파이프라인 개발까지 핵심 개념과 실용적인 기술들을 다룬다. 이 과정에서 ‘LLM Twin’이라는 실제 프로젝트를 통해 개인의 글쓰기 스타일과 성격을 모방하는 AI를 구현하며, 데이터 수집과 전처리, 모델 파인튜닝 등 LLM 엔지니어링의 실전 노하우를 깊이 있게 익힐 수 있다. 이 책이 제시하는 실질적인 로드맵을 따라 데이터 수집부터 모델 최적화까지의 전 과정을 단계별로 학습해보며, LLM 엔지니어링 역량을 한 단계 더 높이길 바란다.
누구를 위한 책 인가요?
무엇을 주로 다루나요?


CHAPTER 1 LLM Twin 개념과 아키텍처 이해
_1.1 LLM Twin 개념
_1.2 LLM Twin의 제품 기획
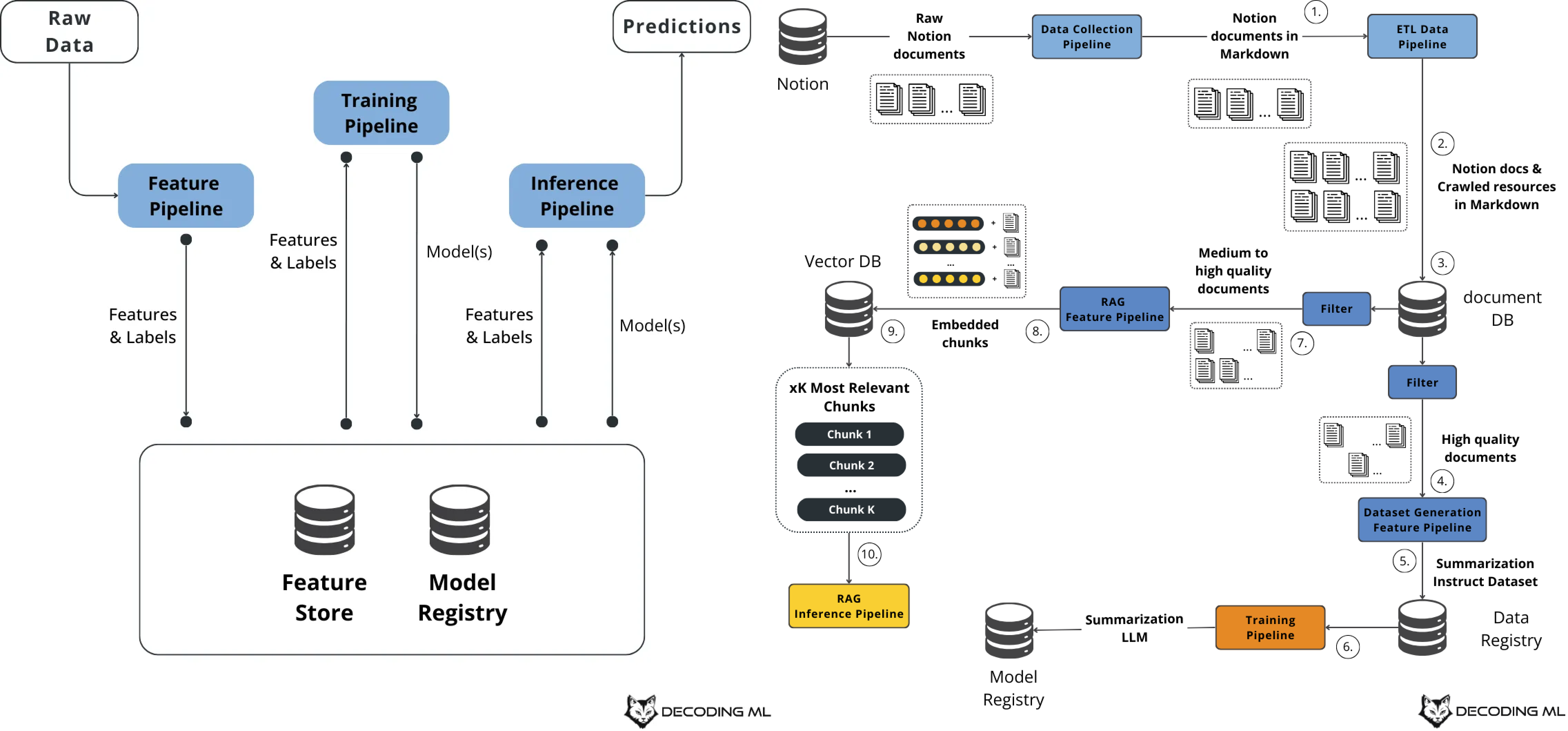
_1.3 특성, 학습, 추론 파이프라인 기반 ML 시스템 개발
_1.4 LLM Twin의 시스템 아키텍처 설계
_요약
_참고 문헌
CHAPTER 2 도구 및 설치
_2.1 파이썬 생태계와 프로젝트 설치
_2.2 MLOps와 LLMOps 도구
_2.3 비정형 데이터와 벡터 데이터를 저장하기 위한 데이터베이스
_2.4 AWS 사용 준비
_요약
_참고 문헌
CHAPTER 3 데이터 엔지니어링
_3.1 LLM Twin의 데이터 수집 파이프라인 설계
_3.2 LLM Twin의 데이터 수집 파이프라인 구현
_3.3 원시 데이터를 데이터 웨어하우스로 수집
_요약
_참고 문헌
CHAPTER 4 RAG 특성 파이프라인
_4.1 RAG 이해
_4.2 고급 RAG 개요
_4.3 LLM Twin의 RAG 특성 파이프라인 아키텍처
_4.4 LLM Twin의 RAG 특성 파이프라인 구현하기
_요약
_참고 문헌
CHAPTER 5 지도 학습 파인튜닝
_5.1 지시문 데이터셋 생성
_5.2 지시문 데이터셋 자체 생성
_5.3 SFT 기법
_5.4 실전 파인튜닝
_요약
_참고 문헌
CHAPTER 6 선호도 정렬을 활용한 파인튜닝
_6.1 선호도 데이터셋 이해
_6.2 선호도 데이터셋 생성
_6.3 선호도 정렬
_6.4 DPO 구현
_요약
_참고 문헌
CHAPTER 7 LLM 평가
_7.1 모델 평가
_7.2 RAG 평가
_7.3 TwinLlama-3.1-8B 평가
_요약
_참고 문헌
CHAPTER 8 추론 최적화
_8.1 모델 최적화 전략
_8.2 모델 병렬 처리
_8.3 모델 양자화
_요약
_참고 문헌
CHAPTER 9 RAG 추론 파이프라인
_9.1 LLM Twin의 RAG 추론 파이프라인 이해
_9.2 LLM Twin의 고급 RAG 기법 탐구
_9.3 LLM Twin의 RAG 추론 파이프라인 구현
_요약
_참고 문헌
CHAPTER 10 추론 파이프라인 배포
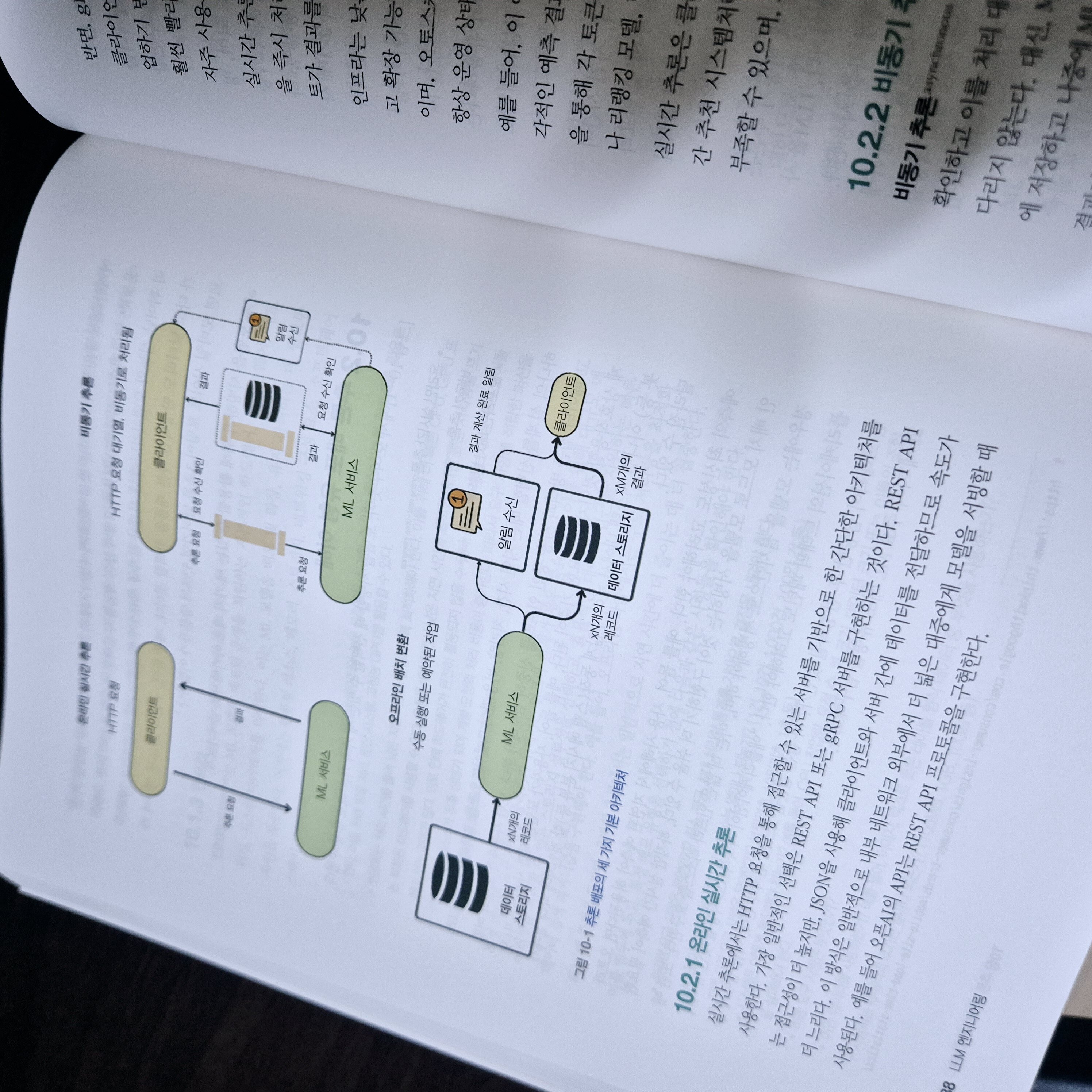
_10.1 배포 유형 선택 기준
_10.2 추론 배포 유형 이해
_10.3 모놀리식 아키텍처와 마이크로서비스 아키텍처 비교
_10.4 LLM Twin의 추론 파이프라인 배포 전략 탐구
_10.5 LLM Twin 서비스를 배포하기
_10.6 급증하는 사용량 처리를 위한 오토스케일링
_요약
_참고 문헌
CHAPTER 11 MLOps와 LLMOps
_11.1 DevOps, MLOps, LLMOps
_11.2 LLM Twin 파이프라인을 클라우드에 배포하기
_11.3 LLM Twin에 LLMOps 적용
_요약
_참고 문헌
APPENDIX MLOps 원칙
_원칙 1: 자동화 또는 운영화
_원칙 2: 버전 관리
_원칙 3: 실험 추적
_원칙 4: 테스트
_원칙 5: 모니터링
_원칙 6: 재현 가능성
나만의 AI를 설계하고 구현하며 배우는
RAG, 파인튜닝(LoRA·QLoRA), FastAPI, LLMOps의 모든 것
챗GPT는 누구나 사용할 수 있지만, 모두에게 ‘맞춤형’은 아닙니다. 일반적인 문체, 장황한 답변, 일관되지 않은 출력은 우리가 원하는 AI와는 다릅니다. 이 책은 단순한 모델 호출을 넘어, 나만의 디지털 AI 캐릭터인 ‘LLM Twin’을 직접 구현하며 실전 LLM 시스템을 개발하는 전 과정을 안내합니다. 웹 스크래핑으로 시작해 RAG 파이프라인 설계, LoRA·QLoRA를 활용한 파인튜닝, 추론 최적화, 클라우드 기반의 LLMOps까지, 이 책은 엔드투엔드 LLM 애플리케이션 개발을 위한 실습형 프로젝트 로드맵을 제공합니다.
이 과정에서 독자는 실제 제품 수준의 시스템을 완성하는 데 필요한 데이터 설계, 인프라 구성, 배포 전략까지 모두 경험하게 됩니다. 미디엄, 서브스택, 깃허브 등 다양한 사이트에서 데이터를 수집해 몽고DB에 적재하고, Qdrant를 활용해 검색 성능을 최적화하며, FastAPI 기반의 RESTful API로 마이크로서비스 구축까지 직접 구현해볼 수 있습니다. 복잡한 LLM 기술을 단순히 설명하는 데 그치지 않고, 이를 실무에 바로 적용할 수 있는 형태로 풀어낸 이 책은 단순히 AI를 ‘활용’하는 것을 넘어 이제는 AI를 ‘직접 만드는’ 시대에 맞춘 실전 가이드입니다. 자신만의 LLM 시스템을 완성하고자 하는 개발자, AI 엔지니어, 기술 리더에게 가장 확실한 길잡이가 되어줄 것입니다.
오탈자 등록