? 한빛미디어 <나는 리뷰어다> 활동을 위해서 책을 제공받아 작성된 서평입니다.
우리가 있는 직장에서 오가는 말들을 한 번 살펴보자.
'대리님, 어제 회의에서 말한 '프로젝트' 이미지소스 좀 부탁해요.', '어제 반려 맞은 '기안서'에 예산 집행계획 다시 써주세요.'
다소 모호해보이는 텍스트지만, 업무 유관자이거나 담당 조직 내 임직원이라면 무엇을 말하는지 알 수 있다.
이는 맥락(Context)를 알고 있기 때문이다.
반대로 해당 업무를 모르고 있는 제3자나 타 부서 임직원은 무엇을 말하는지 무슨 액션을 원하는지 정확하게 파악하기 어려울 것이다.
그럼 혹자는 이렇게 말할지도 모르겠다. 그럼 모든 커뮤니케이션에 자세하고 명확하게 말하면 되는거 아닌가요? 그러기에는 우리의 시간과 비용 모두 한정적이다.
생성형 AI를 위한 프롬프트엔지니어링

이미 대부분의 사람들이 하루도 빼놓지 않고 사용하는 생성형 AI 역시 결과물에 영향을 미치는 가장 큰 요소가 맥락(Context)이다.
이러한 프롬프트를 잘 작성하는 방법 뿐만 아니라 더 나아가 서비스화까지 할 수 있는 프롬프트 엔지니어링 책을 소개하려고 한다.
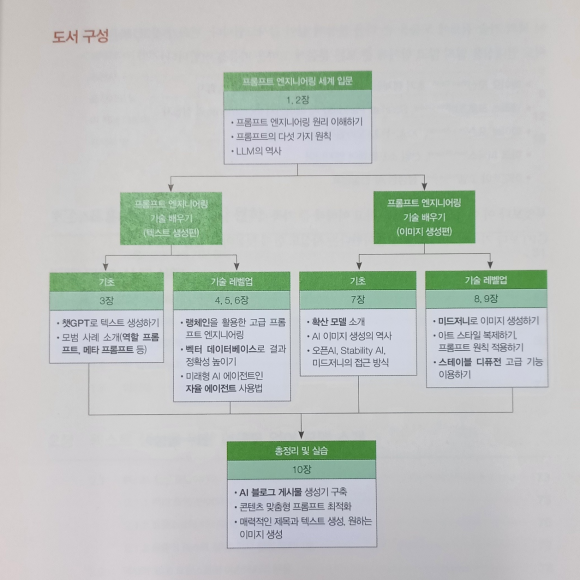
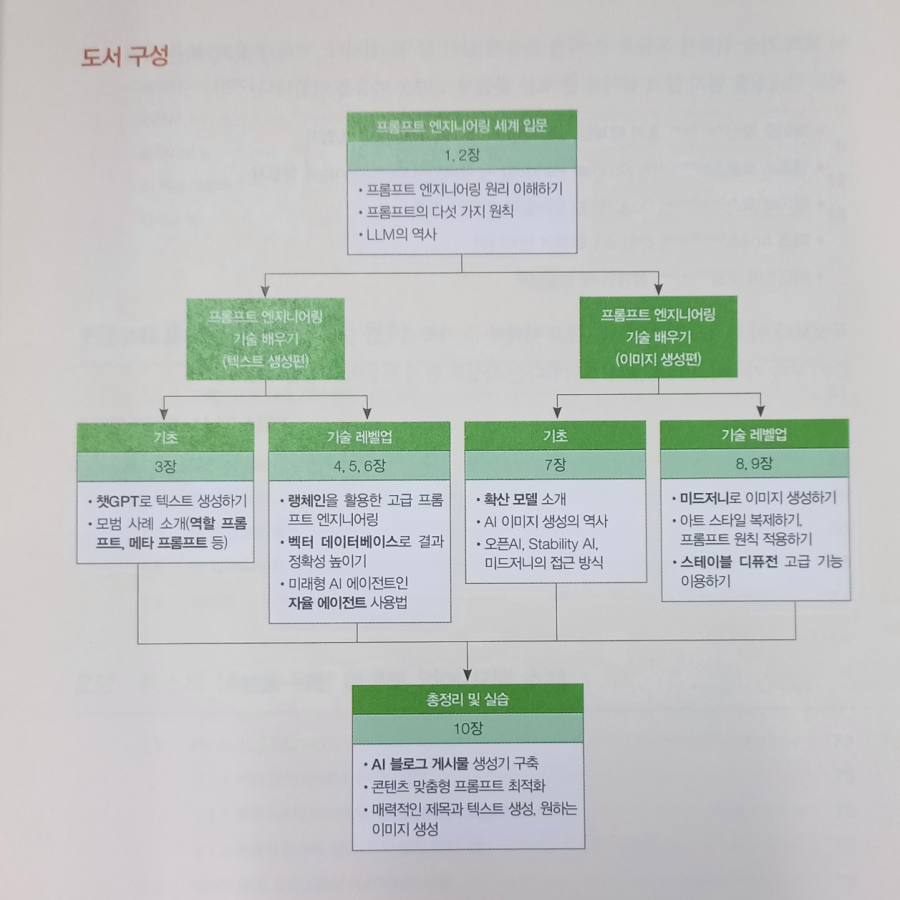
이 책은 우선 1~10장까지 구성되어 있고 아래와 같이 도식화하여 소개했다.
텍스트 생성과 이미지 생성 두 파트로 크게 나눠 설명했고 각 개념에 대한 설명과 예시까지 구성되어 있다.

1장 프롬프트의 다섯 가지 원칙
이 책의 전반적인 내용을 관통하는 프롬프트의 다섯가지 원칙을 소개하고, 대규모 언어모델(LLM)의 역사와 모델의 종류까지 소개하고 있다.
사실 그 동안 GPT 활용법 같은 류들의 책은 많이 봐와서 그런지 크게 새로운 부분 없었지만 프롬프트 예시를 통한 맥락을 통해 정확도를 높이는 방법을 정량화한 내용은 흥미로웠다,
예시가 없는 프롬프트를 제로샷(Zero-shot)이라 부르고, 예시를 하나를 제공하면 원샷(One-shot), 그리고 여러 예제를 제공하면 퓨샷(Few-shot)으로 정의한다.
재밌는 점은 이들간의 정확도인데 예시를 하나만 제시해도 정확도가 급격하게 올라가고 예시의 수를 늘릴수록 정확도는 더 높아진다. 이는 사용되는 파라마터가 많은 모델일수록 더 큰 효과를 낸다.

프롬프트에서 내가 원하는 결과물에 가장 빠르게 도달할 수 있는 방법은 맥락을 제공하는 것이고 그 중 가장 효과적인 방법이 예시라는 것을 알 수 있다. 그러나 너무 많은 예시는 높은 신뢰성을 얻는 대신 창의성은 줄어들 수 있다고 경고한다.
마치 어떤 그림을 그릴 때 템플릿을 정해놓고 디자인 하는 것과 백지 상태에서 그리는 것과의 차이라고 할 수 있다. 어떤 문제냐에 따라서 이 부분을 잘 정의해야 함을 알 수 있었다.
2장 텍스트 생성을 위한 대규모 언어 모델 소개
2장은 LLM 자체가 어떻게 동작하는지 간략히 짚어준다. 이 구조를 알면 왜 우리가 맥락을 그렇게 강조하는지 더 잘 이해할 수 있다.

그 중 기억에 남는 부분은 바로 트랜스포머 아키텍처의 어탠션(Attention)이라는 개념이다.
기존의 정통적인 언어모델인 RNN./LSTM과 같은 순차 모델은 문장이 길어질수록 앞의 정보가 희미해지고 병렬처리가 불가능한 문제가 있었다.
그러나 트랜스포머 기반의 병렬처리 방식을 통해 지금의 LLM 분야가 획기적으로 성장할 수 있었다고 한다. 모든 단어가 동시에 연관도를 계산(Self-Attention)하고 이를 병렬로 처리하다보니 장기 의존성 문제를 해결할 수 있다.
이 역시 GPU 수요를 높였다는 점에서 재밌는 부분이라 할 수 있다
대규모 언어모델을 소개하는 부분에서는 이 책의 원서가 약 1년 전에 나오다보니 다소 구형 모델의 소개하는 페이지가 되어버렸다. 아쉽지만 크게 중요한 부분은 아니니 넘어가도 좋을 것 같다.
AI 모델의 발전속도가 워낙 빠르다보니 발생하는 문제이긴 한데, 옮긴이의 각주를 통해 보충 설명을 해두고 있으니 책을 읽는데는 크게 거슬진 않았다.
3장 챗GPT로 텍스트 생성하기
3장에서는 실제 출력결과를 다루는 방법으로 확장되는데 앞선 1장에서 제시했던 다섯가치 원칙에 근거해 설명하고 있다.
사실 그동안 AI를 사용할 때, 철저한 사용자 관점에서 텍스트나 파이썬 코드 형태로 결과물을 받아 보는데 익숙했는데 여기서는 json이나 yml같은 구조화된 포맷으로도 쉽게 출력할 수 있다는 점이 신선했다.
이전에 Make와 같은 자동화 툴로 MCP(Model Context Protocol)를 다룰 때, json 형태로 받아오긴 했지만 자꾸 오류가 떴던 기억이 나면서 여기서 나온 내용을 바탕으로 다시 만들어봐야겠다는 생각이 들었다.

더 나아가서 업무 중에서 사용하는 자료를 자동화된 형식으로 출력해보는 것도 가능하겠다는 생각도 들었다.
4~6장 랭체인을 활용한 고급 프롬프트 기술, 벡터 데이터베이스
4장에서 6장은 LLM을 직접 만들어 서비스 하는 사람에게 필요한 내용들이 담겨있다. 그렇지 않더라도 LLM을 빌려서 만드는 플랫폼 구조와 그 속에서 텍스트 청킹(Chunking)이 왜 중요한지를 이야기하고 있기 때문에 알아두면 좋을 내용이었다.
나는 사실 LLM을 활용한다고 하면 그냥 API 호출해서 질문과 답변 주고 받는 수준으로만 생각했다. 하지만 책을 읽으면서 서비스의 원리가 훨씬 체계적이라는 걸 알게 됐다.

문서를 일정한 크기로 청킹(Chunking)하고, 그걸 벡터 데이터베이스에 저장해두고 사용자의 질문이 들어오면 관련 있는 chunk만 찾아서 모델에 함께 전달하는 프로세스를 가볍게 이해할 수 있었다.
결국 이러한 모델은 응답시간, 사용 토큰수, 정확도(서비스 품질) 모두 중요하기 때문에 이러한 프롬프트 엔지니어링이 중요하다는 사실도 알게 되었다.
7~9장 이미지 생성을 위한 확산모델
최근 들어 AI를 통한 이미지 생성이 더 이상 디자이너의 영역이 아닌 일반 대중으로 확산되고 있다.
얼마 전 열풍이 불었던 지브리풍 이미지 생성을 떠올려보면 이제 소상공인 수준에서도 이미 활발하게 사용되고 있는 것 같다.
나 역시도 마케팅에서 간단한 이미지는 더 이상 이미지 소스 서비스보다는 직접 생성해서 쓰는 편이다.
7장부터는 이미지 생성의 프롬프트 원리와 설계방법을 소개한다.
텍스트 프롬프트와 크게 다르지 않지망 디퓨전(Diffusion) 모델을 소개하면서 보니 네거티브 프롬프트도 이미지생성에서 중요함을 알게 되었다.

9장에서는 스테이블 디퓨전을 좀 더 깊게 다루는데 리뷰 차원에서 간단하게 훑어본 상태라서 시간 내서 이 부분은 정독하고 실습해볼 예정이다. 이미지의 일부만 수정하거나 업스케일하는 과정까지 다루고 있어 실제로 도움이 많이 될 것 같다.
10장 AI기반의 애플리케이션 구축
마지막 장에서는 앞서 배운 지식을 활용해 실제 애플리케이션을 만드는 방법을 짧게 소개한다. 매우 짧지만 임팩트있게 정리되어 있어서 그동안 하고 싶었지만 미뤄왔던 뉴스 요약하는 AI 모델을 만들어볼 때 참고하면 좋을 것 같다는 생각이 들었다.
마치며
생성형 AI는 이미 많은 것을 바꿔놓았고 앞으로도 많은 부분을 바꿔놓을 것이다.
이 책은 소프트웨어 개발자나 데이터 관련 엔지니어 외에도 활용하는 사용자나 서비스 기획자 입장에서도 읽어보면서 참고하면 좋을 내용들이 담겨있다.
그동안 가벼운 내용의 GPT 활용 관련 책만 읽었는데 책의 내용을 100% 이해하진 못했지만 프롬프트 엔지니어링에 대한 작게나마 이해할 수 있게 된 것 같다.
? 한빛미디어 <나는 리뷰어다> 활동을 위해서 책을 제공받아 작성된 서평입니다.