![]() 발리아파 락슈마난, 하네스 하프케
발리아파 락슈마난, 하네스 하프케
2026-05-08
![]() 1.9K
1.9K
오늘은 요즘 개발자 사이에서 가장 뜨거운 주제인 ‘AI 에이전트’의 핵심 원리를 하나 파헤쳐 보려고 합니다.

LLM 기반 챗봇에게 “6월 12일 모리셔스발 이스탄불행 항공편 예약해 줘”라고 말하면, 아주 그럴듯한 답변이 돌아옵니다. 항공편 코드, 출발 시간, 좌석 등급까지 깔끔하게 정리해서요.
그런데 잠깐, 진짜로 예약이 된 걸까요?
당연히 아닙니다.
LLM은 텍스트를 생성하는 기술이지, 항공사 API를 호출해서 결제를 처리하는 기술이 아니니까요. 다시 말해 “환불이 처리되었습니다”라는 이메일 문구는 거뜬히 만들어 내지만, 실제로 은행 계좌에 돈이 입금되게 할 수는 없습니다.
그런데 요즘 AI 에이전트들은 정말로 항공편을 예약하고, 날씨를 검색하고, 데이터베이스를 조회합니다. 어떻게 이런 작업이 가능한 걸까요? 그 비밀이 바로 ‘도구 호출(Tool Calling)’ 패턴입니다.
LLM이 할 수 있는 것과 할 수 없는 것의 경계를 먼저 명확히 해 봅시다. LLM은 텍스트, 이미지, 오디오, 비디오 같은 콘텐츠를 생성합니다. 여기에 RAG를 붙이면 기업 내부 문서나 최신 정보까지 반영한 답변도 가능합니다. 이것만으로도 연구 보고서 작성, 번역, 코드 생성 같은 일에는 충분합니다.
하지만 소프트웨어가 하는 일은 그게 전부가 아닙니다. 수치 계산, 항공편 예약, 환불 처리, 이메일 발송... 이런 작업은 LLM의 텍스트 생성 능력만으로는 처리할 수 없습니다. 바로 이 지점, LLM이 외부 세계와 상호작용할 수 있게 되는 순간부터 애플리케이션을 ‘에이전틱(agentic)’이라고 부를 수 있게 됩니다.
항공편 예약 예제로 보면 도구 호출의 흐름은 꽤 단순합니다. 핵심은 LLM이 직접 예약을 수행하는 것이 아니라, 어떤 도구를 어떤 인수로 호출해야 하는지 판단한다는 점입니다.
먼저 실제로 항공편을 예약하는 함수를 개발자가 직접 구현합니다. 항공사 API를 호출해서 예약 결과를 돌려주는 book_flight 같은 함수를요.
함수 이름, 인수 설명, 반환값 정보를 JSON 형태로 정리해서 LLM에게 전달합니다. LLM은 이 ‘도구 목록’을 보고 상황에 맞는 함수를 고를 수 있게 됩니다.
여기가 핵심입니다. LLM은 함수를 직접 실행하지 않습니다. 대신 "book_flight 함수를 이런 인수로 호출하면 돼"라는 구조화된 요청을 생성합니다. LLM 자체는 텍스트(JSON)를 출력하는 모델이지 코드 실행 환경이 아니기 때문이죠. 이 분리 덕분에 보안 측면에서도 이점이 큽니다. 악의적 입력으로 임의의 코드가 실행되는 것을 애플리케이션 레이어에서 검증·차단할 수 있으니까요.
개발자가 작성한 코드(클라이언트)가 LLM의 지시대로 함수를 실행합니다. 그리고 그 결과인 예약 확인 번호, 좌석 정보, 결제 금액 등을 다시 LLM에 전달합니다.
LLM은 함수 실행 결과를 바탕으로 사용자에게 보여 줄 최종 메시지를 자연스럽게 작성합니다. “예약이 완료되었습니다. 예약 번호는 ABC123이고…”와 같은 식으로요. 이 과정을 한마디로 정리하면 LLM은 ‘무엇을 해야 할지’ 판단하고, 실제 ‘행동’은 검증된 코드가 담당한다는 겁니다.
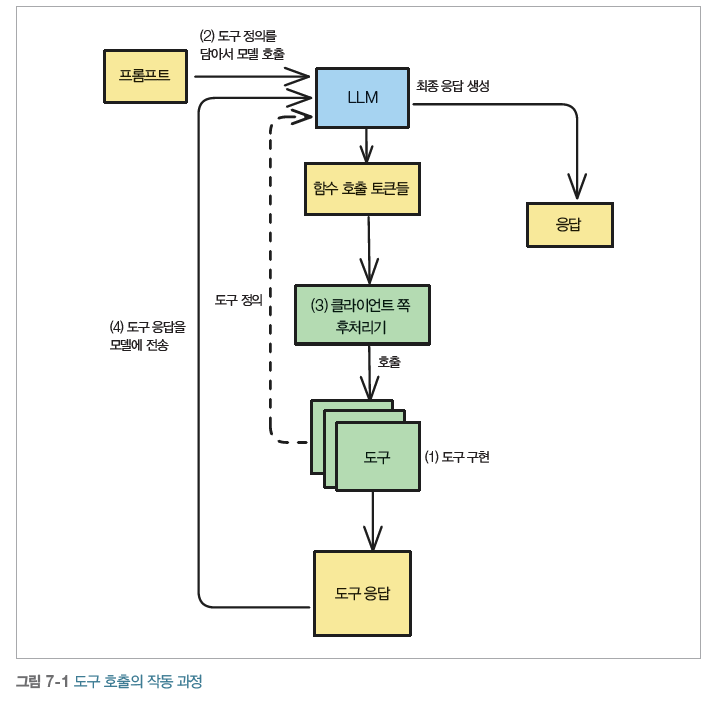
여기서 중요한 것은 LLM의 출력이 곧바로 실행되는 코드가 아니라는 점입니다. 모델은 보통 tool_call 또는 function_call 형태의 구조화된 출력을 생성하고, 실제 실행 여부는 애플리케이션 레이어가 검증한 뒤 결정합니다. 이때 인수 검증, 권한 확인, 사용자 승인, 실행 로그 기록 같은 단계가 함께 설계되어야 합니다.
도구를 호출할 수 있게 되면 LLM의 활용 범위가 폭발적으로 넓어집니다. 실제 서비스에서는 도구 호출이 다음과 같은 문제를 해결하는 데 자주 쓰입니다.
RAG가 미리 색인화된 정적 데이터에 강하다면, 도구 호출은 현재 뉴스, 실시간 날씨, 주가 같은 동적 데이터를 가져오는 데 유용합니다.
이메일, 캘린더, 업무 도구와 연결하면 LLM이 개인 맥락에 맞는 응답을 생성할 수 있습니다.
최신 LLM은 단순 산술이나 추론 기반 계산은 꽤 잘하지만, 높은 정밀도가 필요한 금융 계산이나 대규모 수치 연산, GIS 분석, 최적화 같은 작업에서는 여전히 한계가 있습니다. 이럴 때 계산기, 솔버, 분석 라이브러리를 도구로 붙이면 정확하고 검증 가능한 결과를 얻을 수 있습니다.
사고 연쇄(CoT) 패턴으로 단계를 세우고, 각 단계에서 도구를 실제로 호출하고, 그 결과에 따라 다음 행동을 수정하는 방식입니다.
여기서 특히 주목할 부분은 MCP(Model Context Protocol) 입니다. 앞서 본 5단계 과정은 LLM API를 직접 다루며 도구 호출 흐름을 수동으로 관리하는 방식이었습니다. 실무에서 이를 매번 수동으로 처리하면 꽤 번거롭습니다. 게다가 도구 정의 방식이 LLM마다 다릅니다. 예를 들어 앤트로픽은 input_schema라는 이름으로 도구의 인수 스키마를 정의하지만, 오픈AI나 라마 계열은 function 객체 안에 parameters 필드를 두는 식이죠.
MCP는 이런 차이를 추상화합니다. 개발자는 함수 위에 @mcp.tool() 데코레이터 하나만 붙이면 됩니다. MCP 서버가 도구를 표준화된 방식으로 노출하고, 클라이언트가 거기에 접속해서 사용하는 구조입니다.
예를 들어, 날씨를 조회할 때는 지오코딩 도구와 날씨 API 도구를 MCP 서버로 만들어 두고, 랭그래프(LangGraph)의 ReAct 에이전트가 이를 자동으로 호출합니다. "시카고의 화요일 날씨는 어때?"라는 질문 하나에, 에이전트가 알아서 시카고의 좌표를 찾고, 그 좌표로 미국 국립기상청 API를 조회하고, 결과를 자연어로 정리해 줍니다.
그래서, 도구 호출을 잘 하려면? 우선 몇 가지 핵심만 짚어보면 이렇습니다.
도구 호출의 정확도는 모델이 도구를 얼마나 잘 이해하느냐에 달려 있습니다. 함수 이름은 명확하게, 독스트링은 상세하게 작성하는 것이 중요합니다. 도구 함수가 그 자체로 설명이 되는 프롬프트 역할을 해야 합니다.
도구가 많을수록 모델이 적절한 도구를 고르는 정확도는 떨어지는 경향이 있습니다. 최신 모델들은 수십 개에서 그 이상의 도구도 다룰 수 있지만, 비슷한 기능의 도구가 섞이면 혼동이 커지므로 가능한 한 도구를 작게 묶고 역할을 명확히 분리하는 게 좋습니다.
LLM이 외부 도구를 호출할 수 있게 되면 프롬프트 주입 공격의 위험도 커집니다. 행동 선택기, 계획 후 실행, 이중 LLM 등 6가지 가드레일 패턴을 함께 알아두면 좋습니다.
결국 AI 에이전트의 핵심은 LLM이 모든 일을 직접 처리하는 데 있지 않습니다. LLM은 사용자의 의도를 이해하고, 어떤 도구를 써야 할지 판단하며, 실제 실행은 검증된 코드와 외부 시스템이 담당합니다. 그래서 앞으로 AI 서비스를 설계할 때 중요한 질문은 “모델이 얼마나 똑똑한가?”에서 한 걸음 더 나아가야 합니다.
“이 모델이 어떤 도구를 안전하게, 정확하게, 필요한 순간에 호출할 수 있는가?”
이 질문에 답할 수 있을 때, 비로소 챗봇은 단순한 대화창을 넘어 실제 일을 처리하는 에이전트가 될 것입니다.
위 콘텐츠는 『에이전트 시대의 AI 시스템 설계』에서 발췌하여 정리하였습니다.

![]() 0
0




댓글