![]() 제이 알아마르, 마르턴 흐루턴도르스트
제이 알아마르, 마르턴 흐루턴도르스트
2025-06-04
![]() 28.6K
28.6K
텍스트만 이해하던 LLM은 이제 이미지를 보고, 음성을 듣고, 동작을 해석할 수 있습니다. 오픈AI의 GPT-4o, 구글의 Gemini 같은 최신 모델은 이제 이미지와 언어를 함께 처리할 수 있는 멀티모달 LLM으로 진화했습니다.
이런 흐름의 핵심에는 비전 트랜스포머(ViT)와 이를 기반으로 언어 모델과 시각 모델을 연결하는 다양한 아키텍처가 있습니다. 지금 우리가 쓰는 언어 모델은 어떻게 세상을 ‘읽는지’ 그 방법을 알아볼까요?
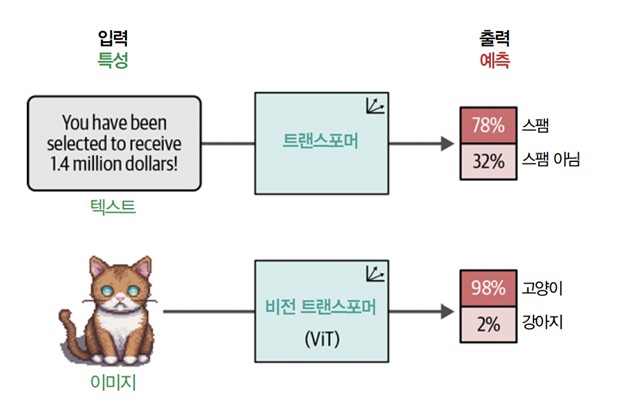
트랜스포머 기반 모델은 다양한 언어 모델링 작업을 성공적으로 해냈습니다. 따라서 연구자들이 트랜스포머의 성공을 컴퓨터 비전 분야로 일반화하는 방법을 찾으려 하는 것은 놀라운 일이 아닙니다. 그들이 찾은 방법을 비전 트랜스포머Vision Transformer (ViT)라고 부릅니다. 종전의 합성곱 신경망 CNN에 비해 이미지 인식 작업에서 매우 잘 동작한다는 것이 입증되었습니다. [그림 1]과 같이 ViT를 사용하면 비정형 데이터인 이미지를 분류와 같은 다양한 작업에 사용할 수 있는 표현으로 바꿀 수 있습니다.
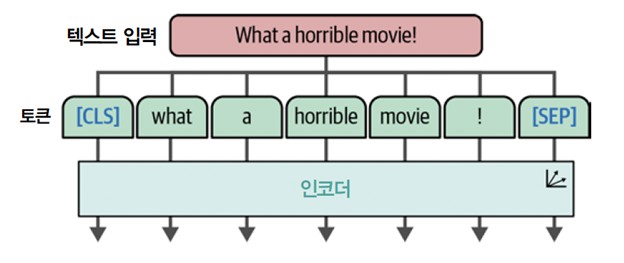
ViT는 트랜스포머 구조의 핵심 구성 요소인 인코더에 의존합니다. 인코더는 텍스트 입력을 디코더에 전달하기 전에 수치 표현으로 바꾸는 역할을 합니다. 하지만 인코더가 제 역할을 수행하기 전에 텍스트 입력이 먼저 토큰으로 바뀌어야 합니다(그림 2).
이미지는 단어로 구성되지 않기 때문에 이런 토큰화 단계를 비전 데이터에 사용할 수 없습니다. 대신 ViT 저자들은 이미지를 ‘단어’로 토큰화하는 방법을 만들었습니다. 이를 통해 원본 인코더 구조를 사용할 수 있습니다.
여기, 고양이 이미지가 있습니다. 이 이미지는 여러 개의 픽셀로 표현됩니다. 가령 512×512 픽셀로 이루어진 이미지는 각 픽셀은 많은 정보를 담고 있지 않지만 픽셀의 패치patch를 연결하면 점차 더 많은 정보가 드러납니다.
ViT는 이와 유사한 원리를 사용합니다. 텍스트를 토큰으로 분할하는 것처럼 원본 이미지를 이미지 패치로 변환합니다. 다른 말로 하면 [그림 3]처럼 이미지를 수평과 수직 방향으로 여러 개의 조각으로 자릅니다.
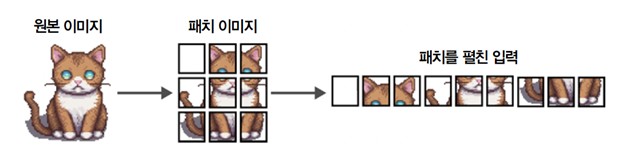
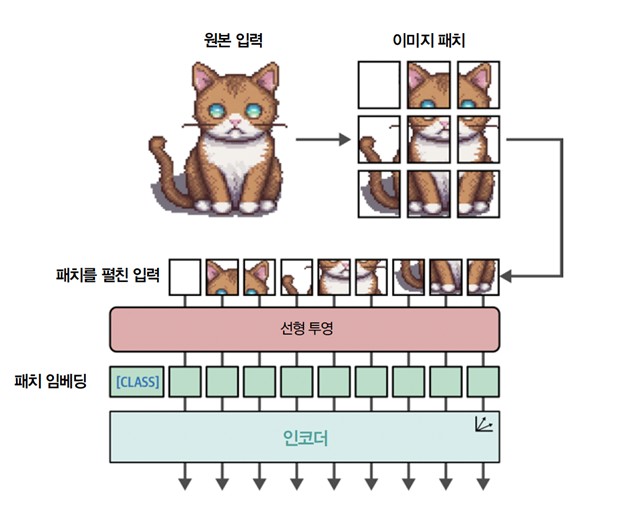
텍스트를 토큰으로 변환하는 것처럼 이미지를 이미지의 패치로 바꿉니다. 이미지 패치를 펼친 입력을 텍스트에 있는 토큰으로 생각할 수 있습니다. 하지만 토큰과 달리 각 패치에 고유한 ID를 할당할 수 없습니다. 텍스트 어휘사전에 있는 토큰과 달리 이런 패치는 다른 이미지에 나타나는 경우가 거의 없기 때문입니다.
그 대신 패치를 선형적으로 임베딩하여 수치 표현, 즉 임베딩을 만듭니다. 이를 트랜스포머 모델의 입력으로 사용합니다. 이런 식으로 이미지 패치를 토큰과 동일한 방식으로 다룹니다. 전체 과정이 [그림 4]에 나타나 있습니다.
설명을 위해 샘플 이미지를 3×3 크기 패치로 나누었습니다. 하지만 원본 ViT 모델은 16×16 크기 패치를 사용합니다. 그래서 이 논문의 제목이 <An Image is Worth 16x16 Words>입니다.
이 방식에서 흥미로운 점은 이 임베딩이 인코더로 전달되면 텍스트 토큰처럼 처리된다는 것입니다. 이 시점부터 텍스트와 이미지를 훈련하는 방식에 차이가 없습니다.
밑바닥부터 멀티모달 언어 모델을 만들려면 엄청난 양의 컴퓨팅 전력과 데이터가 필요합니다. 이런 모델을 훈련하려면 수십억 개의 이미지, 텍스트, 이미지-텍스트 쌍을 사용해야 합니다. 상상할 수 있겠지만 현실적으로 매우 어렵습니다!
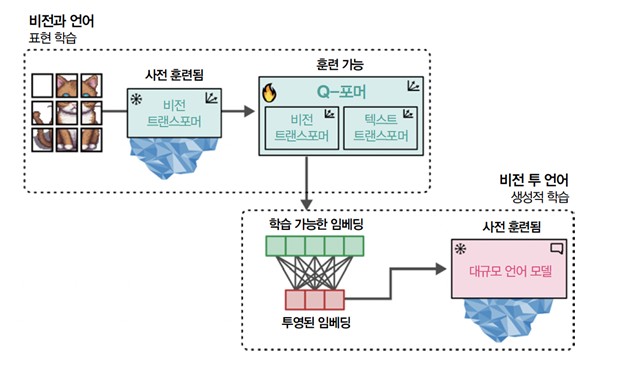
BLIP-2는 밑바닥부터 모델을 구축하는 대신 Q-포머Querying Transformer로 비전과 언어 사이의 간극을 메꿉니다. 이를 위해 Q-포머는 사전 훈련된 이미지 인코더와 사전 훈련된 LLM 사이에 다리를 연결합니다. 사전 훈련된 모델을 활용하므로 밑바닥부터 이미지 인코더와 LLM을 훈련할 필요 없이 BLIP-2는 다리만 훈련하면 됩니다. 이미 존재하는 기술과 모델을 잘 활용한 것이죠! 이 다리가 [그림 5]에 나타나 있습니다.
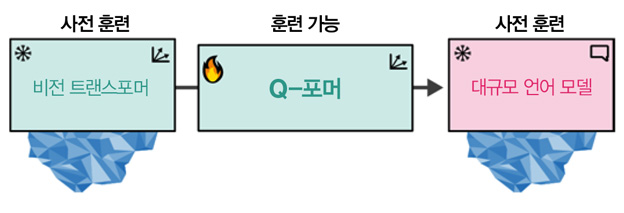
두 개의 사전 훈련된 모델을 연결하기 위해 Q-포머는 이들의 구조를 흉내냅니다. Q-포머는 어텐션 층을 공유하는 두 개의 모듈로 구성됩니다.
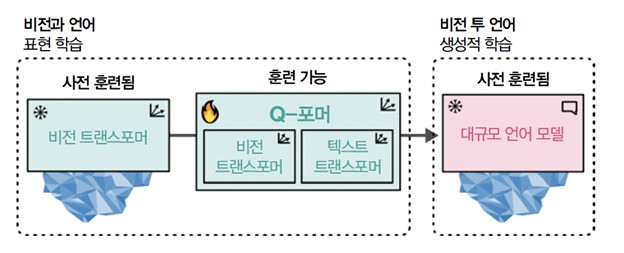
[그림 6]에 나타나 있듯이 Q-포머는 모달리티마다 하나씩 두 단계로 훈련됩니다.
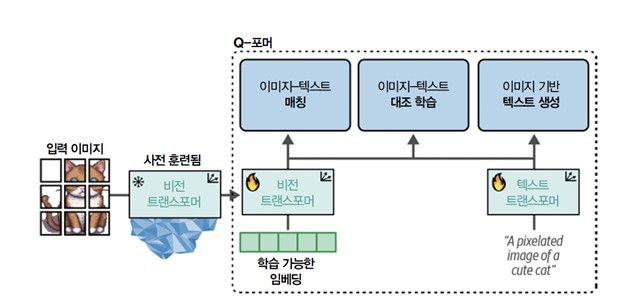
단계 1에서 이미지-문서 쌍을 사용해 이미지와 텍스트를 모두 표현하도록 Q-포머를 훈련합니다. CLIP을 훈련할 때 보았듯이 이 데이터 쌍은 일반적으로 이미지 캡션입니다. 이미지를 동결된 ViT에 주입하여 비전 임베딩을 얻습니다. 이 임베딩을 Q-포머의 비전 트랜스포머를 위한 입력으로 사용합니다. 캡션은 Q-포머의 텍스트 트랜스포머에 입력됩니다.
이런 입력을 사용해 Q-포머는 세 가지 작업에서 훈련됩니다.
이런 세 개의 목적이 함께 최적화되어 동결된 ViT에서 추출한 시각 표현을 향상시킵니다. 어떤 면에서는 나중에 LLM에 사용할 수 있도록 동결된 ViT의 임베딩에 텍스트 정보를 주입하는 것과 같습니다. BLIP-2의 첫 단계가 [그림 7]에 나타나 있습니다.
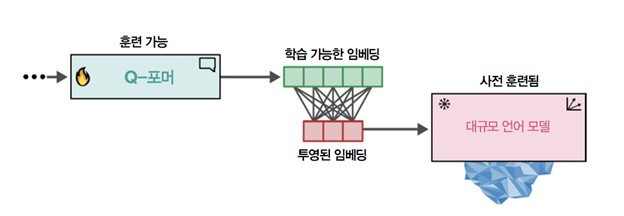
단계 1에서 얻은 학습 가능한 임베딩에는 텍스트 정보와 동일한 차원 공간에 시각 정보가 담깁니다. 단계 2에서 이 학습 가능한 임베딩을 LLM에게 전달합니다. 어떤 면에서 이 임베딩은 Q-포머에서 추출한 시각 정보로 LLM에게 조건을 부여하는 소프트 시각 프롬프트로 동작합니다.
또한 그 사이에는 학습 가능한 임베딩을 LLM이 기대하는 크기에 맞추기 위한 완전 연결 층이 있습니다. 비전을 언어로 바꾸는 이 두 번째 단계가 [그림 8]에 나타나 있습니다.
이 두 단계를 합치면 Q-포머가 동일 차원의 공간에서 시각 표현과 텍스트 표현을 학습할 수 있습니다. 이를 LLM의 소프트 프롬프트로 사용합니다. 결과적으로 프롬프트로 LLM에게 문맥을 제공하는 것과 비슷한 방식으로 이미지에 대한 정보를 제공할 수 있습니다. [그림 9]에 전 과정이 나타나 있습니다.
BLIP-2 이후로 프로세스가 비슷한 시각 LLM이 많이 출시되었습니다. 텍스트 LLM을 멀티모달로 만들기 위한 프레임워크인 LLaVA나 미스트랄 7B LLM 기반의 효율적인 시각 LLM인 Idefics 2 등입니다. 두 시각 LLM은 구조가 다르지만 모두 CLIP과 유사한 사전 훈련된 비전 인코더와 텍스트 LLM을 연결합니다. 이런 구조의 목표는 입력 이미지에서 얻은 시각 특성을 언어 임베딩에 투영하여 LLM의 입력으로 사용할 수 있게 만드는 것입니다. Q-포머와 비슷하게 이미지와 텍스트 사이의 간극을 메우려는 시도입니다.
BLIP-2와 같은 모델을 사용하는 가장 간단한 예는 이미지 캡션을 만드는 것입니다. 의류 상품의 설명을 만들고 싶은 상점이나 1,000장이 넘는 결혼식 사진에 수동으로 레이블을 붙일 시간이 없는 사진가를 상상해 보세요.
이미지 캡션을 만드는 과정은 이전에 본 전처리 과정과 비슷합니다. 이미지를 모델이 해석할 수 있는 픽셀 값으로 변환합니다. 이 픽셀 값을 BLIP-2에 전달하여 소프트 시각 프롬프트로 변환합니다. 그다음 LLM이 이를 사용해 적절한 캡션을 생성합니다. 전체적인 과정을 살펴보도록 하겠습니다.
먼저, 전처리기를 사용해 슈퍼카 이미지를 기대하는 픽셀 값으로 변환합니다.
# AI가 생성한 슈퍼카 이미지를 로드합니다.
image = Image.open(urlopen(car_path)).convert("RGB")
# 이미지를 전처리하여 입력을 준비합니다.
inputs = blip_processor(image, return_tensors="pt").to(device, torch.float16)
show_image(inputs)

다음 단계는 BLIP-2 모델을 사용해 이미지를 토큰 ID로 변환하는 것입니다. 그다음 이 ID를 텍스트(생성된 캡션)로 변환할 수 있습니다.
# 이미지 임베딩을 만들고 Q-포머의 출력을 디코더(LLM)에 전달해 토큰 ID를 생성합니다.
generated_ids = model.generate(**inputs, max_new_tokens=20)
# 토큰 ID를 바탕으로 텍스트를 생성합니다.
generated_text = blip_processor.batch_decode(generated_ids, skip_special_tokens=True)
generated_text = generated_text[0].strip()
generated_text
generated_text에 다음과 같은 캡션이 담겨 있습니다.
an orange supercar driving on the road at sunset
# 석양을 등지고 달리는 오렌지빛 슈퍼카
자동차 이미지를 완벽하게 설명한 것 같군요!
이미지 캡션 생성은 더 복잡한 사용 사례를 다루기 전에 모델에 대해 배울 수 있는 좋은 방법입니다. 자신만의 이미지로 몇 번 더 테스트해 보고 잘 작동하는 경우와 그렇지 않은 경우를 확인해 보세요. 특정 만화 캐릭터나 가상의 창조물과 같은 특정 도메인의 이미지는 캡션을 잘 만들지 못할 수 있습니다. 이 모델은 대량의 공개 데이터에서 훈련되었기 때문입니다.
이 예제를 마치기 전에 로르샤흐 검사Rorschach test에 사용되는 이미지(그림 10)를 가지고 테스트해 보겠습니다. 잉크 무늬를 무엇으로 보는지로 그 사람의 성격에 대해 알아보는 심리학 검사입니다. 상당히 주관적인 테스트인데 이걸로 LLM의 성격을 알아보면 어떨까요!
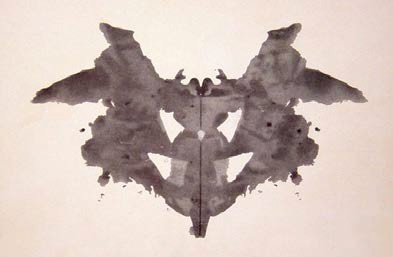
# 로르샤흐 이미지를 로드합니다.
url = "https://bit.ly/3GJmrra"
image = Image.open(urlopen(url)).convert("RGB")
# 캡션을 생성합니다.
inputs = blip_processor(image, return_tensors="pt").to(device, torch.float16)
generated_ids = model.generate(**inputs, max_new_tokens=20)
generated_text = blip_processor.batch_decode(
generated_ids, skip_special_tokens=True
)
generated_text = generated_text[0].strip()
generated_text
이전처럼 generated_text에 생성된 캡션이 담겨 있습니다. LLM의 성격을 알아보는 건 여러분의 몫으로 남기겠습니다.
위 콘텐츠는 『핸즈온 LLM』의 내용을 재구성하여 작성하였습니다.

![]() 0
0




댓글