![]() 로런스 모로니
로런스 모로니
2026-03-05
![]() 4.4K
4.4K
AI가 사람의 언어를 이해하고, 심지어 문장에 담긴 ‘긍정’과 ‘부정’, ‘빈정거림’의 감정까지 파악하는 것을 보면 신기할 때가 많습니다. 컴퓨터는 근본적으로 숫자만 이해할 수 있는데, 도대체 어떻게 텍스트의 미묘한 ‘의미’를 파악하는 걸까요?

단순히 단어에 고유한 번호를 부여하는 것만으로는 문맥을 파악하기에 부족합니다. 단어의 의미를 절대적인 수치로 완벽하게 인코딩하는 방법은 없지만, 단어들 사이의 ‘상대적인 관계’를 통해 의미를 유도하는 것은 가능합니다.『파이토치로 배우는 LLM & AI』 6장에서는 컴퓨터가 단어의 의미를 학습하는 과정을 아주 직관적이고 재미있는 비유로 설명합니다.
지금부터 우리가 기사의 제목(헤드라인)을 분류하는 AI를 만든다고 상상해 봅시다. AI에게 기사 제목이 정상적인지, 혹은 빈정거리는 단어가 포함되어 있는지 확인하게끔 주문하려고 합니다. 가장 단순하게는 문장에 등장한 단어에 따라 빈정거리는 의미에는 1을 더하고 (+1), 정상적인 단어에는 1을 빼는 방식(-1)을 쓸 수 있습니다.

이렇게 수천 번을 반복하면 빈정거리는 뉘앙스를 가진 단어들은 큰 양숫값을, 평범한 단어들은 음숫값을 가지게 됩니다. 단어의 의미를 어느 정도 이해하는 데는 도움이 되지만, 이 방법은 한 방향(1차원)으로만 점수가 매겨지기 때문에 언어의 미묘한 뉘앙스를 모두 담아내기에는 한계가 있습니다.
그렇다면 단어가 가진 더 많은 정보를 얻기 위해 ‘방향의 차원’을 증가시키면 어떨까요?
책에서는 제인 오스틴의 명작 소설 『오만과 편견』의 등장인물들을 통해 이 복잡한 개념을 시각적으로 풀어냅니다.
소설 속 등장인물들을 2차원 그래프에 배치해 본다고 상상해 봅시다. 이때 그래프는 남성과 여성(X축), 귀족과 평민 (Y축), 각 인물의 재산 규모 (벡터의 길이)를 나타냅니다.
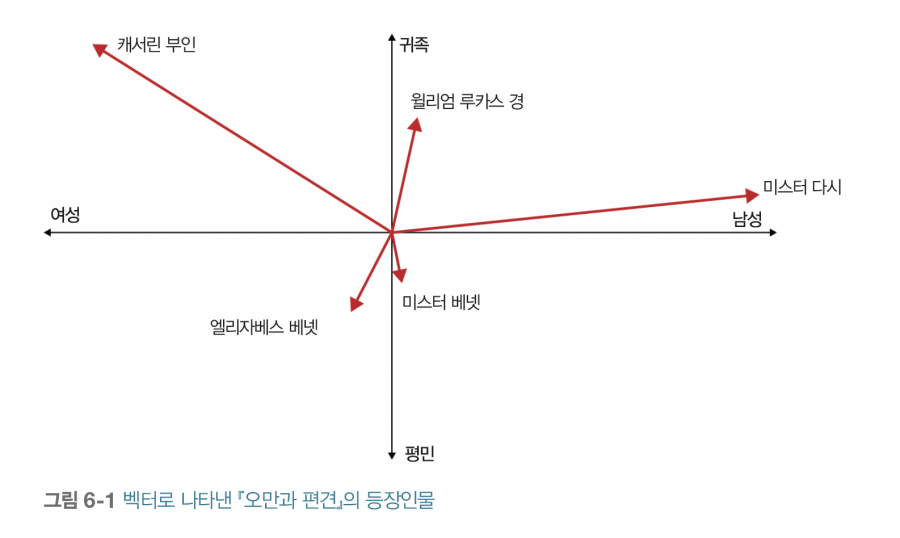
그래프를 살펴보면 남자 주인공인 미스터 다시는 남성이며 매우 부유한 것을 확인할 수 있습니다. 반면 엘리자베스 베넷은 평민 계급의 여성이며, 재정적으로 어려움을 겪고 있을 것이라는 걸 알 수 있죠. 또 다른 등장인물인 캐서린 부인은 여성이며 매우 부유한 귀족이며, 미스터 베넷은 평민 남성임을 파악할 수 있습니다.
이 그래프의 가장 흥미로운 점은 등장인물을 나타내는 두 벡터 사이의 방향이 그들 관계의 본질을 알려 준다는 것입니다.
예를 들어 부유한 남성인 ‘미스터 다시’의 위치에서 평민 여성인 ‘엘리자베스’를 향해 화살표(방향)를 그려보면 어떨까요? 이 둘 사이를 가로지르는 거대한 방향성은 단순한 선이 아니라, 소설의 핵심 주제인 계급 차이와 그에 따른 ‘오만과 편견’을 시각적으로 나타냅니다.
AI가 텍스트를 읽을 때 사용하는 방식이 바로 이것입니다. 고차원 공간의 벡터로 단어를 표현하는 이 기술을 AI에서는 ‘임베딩(embedding)’이라고 부릅니다.
실제 자연어 처리(NLP)에서는 ‘성별’이나 ‘계급’이라는 2개의 축(차원)이 아니라, 수십에서 수백 개에 달하는 차원을 사용합니다. AI는 이 거대한 다차원 공간 안에서 단어들이 어떻게 뭉쳐 있고 어떤 방향으로 연결되는지 파악함으로써, 비슷한 의미를 가진 단어들을 묶고 문장의 숨은 감성을 이해하게 됩니다.
복잡한 수학 공식 없이도 AI의 언어 이해 방식을 깨닫게 해주는 정말 매력적인 비유 아닐까요?
단순한 텍스트가 숫자의 배열로 바뀌고, 마침내 감정을 가진 벡터 공간으로 재탄생하는 구체적인 코드가 궁금하다면, 지금 『파이토치로 배우는 LLM & AI』를 펼쳐보세요!

![]() 0
0




댓글