IT/모바일
이미지 생성 모델은 최근 몇 년 동안 발전하여, 사람들이 생각하는 것보다 더욱 세밀하고 현실적인 이미지를 생성할 수 있게 되었습니다. 혁신적인 알고리즘을 구축하고, 대규모 데이터로 학습한 덕분이죠. 어떻게 그토록 정교한 이미지를 생성해 낼 수 있게 되었을까요?
✅합성곱 오토인코더
합성곱 신경망Convolution Neural Network, CNN은 이미지 처리 분야에 탁월한 성능을 보입니다. 특히 이미지에 담긴 사물이 어떤 것인지 예측하는 작업, 즉 이미지 분류image classification에 뛰어나죠.
합성곱 신경망은 합성곱 층convolution layer과 필터filter를 사용하여 이미지의 특징을 스캔합니다. 합성곱 신경망의 구조를 그림으로 표현하면 다음과 같습니다. 합성곱 층은 이미지를 연산한 값을 담은 캔버스로, 필터는 캔버스 위의 이미지를 감지하는 도장으로 묘사했습니다. 필터가 입력 데이터 위를 마치 도장을 찍듯 움직이기 때문이죠.
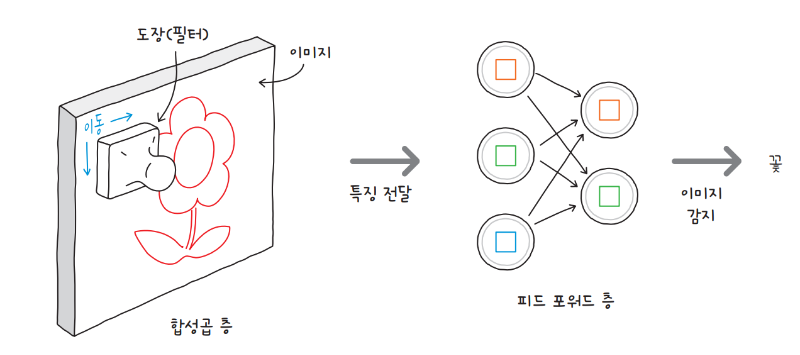
복잡한 연산을 수행하기 위해 인공 신경망의 뉴런을 여러 개 나열한 것을 층layer이라고 합니다. 합성곱 층은 이름 그대로 합성곱 연산을 수행하는 인공 신경망의 층입니다. 그리고 필터가 바로 뉴런에 해당하는 개념이죠.
일반적으로 이미지를 처리하려면 하나의 합성곱 층에 수십에서 수백 개의 필터가 필요합니다. 필터는 합성곱 층을 수직, 수평 방향으로 이동하며 이미지의 특징을 감지하죠. 그리고 유용한 정보를 피드 포워드 층feed forward layer에 전달합니다. 이 과정을 거치며 합성곱 신경망은 이미지에 담긴 사물이 무엇인지 예측하는데, 이미지 분류라 일컫는 작업이 이것입니다.

<구글의 이미지 속 객체 탐지 기술>
합성곱 신경망은 이미지 분류에 효과적이지만, 새로운 이미지를 생성하는 데는 널리 활용되지 못했습니다. 하지만 오토인코더autoencoder와 만나며 이미지 생성에도 본격적으로 쓰이기 시작했죠.
오토인코더는 단순히 말하면 입력 데이터를 복원하여 출력하는 신경망입니다. 흔히 입력 데이터를 재구성한다고 표현하는데, 입력과 출력이 동일하다니 언뜻 아무 소용 없는 작업같이 보입니다. 하지만 오토인코더는 신경망에 병목 지점을 만들어서 입력 데이터가 병목 지점을 통과하게 만들고, 병목 지점에 유용한 정보를 남김으로써 새로운 데이터를 생성합니다.
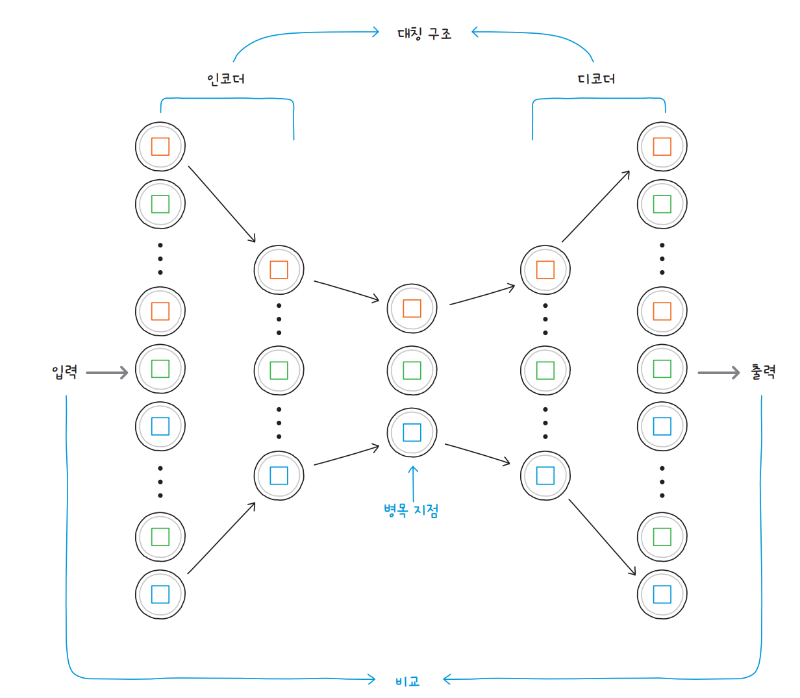
오토인코더는 병목 지점을 기준으로 인코더와 디코더가 대칭인 구조입니다. 인코더는 입력 데이터를 압축해 병목 지점을 통과시킵니다. 그리고 디코더는 병목 지점을 지나 온 데이터를 다시 원본 크기로 확장하죠. 그리고 디코더의 출력을 입력과 비교하여 얼마나 잘 복원했는지를 평가합니다.
오토인코더의 핵심은 병목 지점에 압축된 입력 데이터의 유용함입니다. 출력 데이터와 입력 데이터가 같으려면 이미지에서 유용한 특징을 압축해야 하기 때문입니다. 이 병목 지점을 잠재 표현latent representation 또는 잠재 변수latent variable라고 합니다.
인코더와 디코더로 합성곱 신경망을 사용한 오토인코더를 합성곱 오토인코더라고 합니다. 합성곱 오토인코더의 인코더는 일반적인 합성곱 층으로, 이미지의 특징을 찾아 유용한 정보로 압축합니다. 그리고 디코더가 원본 이미지를 복원하는데, 이때 사용되는 합성곱 층이 전치 합성곱 층transposed convolution layer입니다. 전치 합성곱 층은 일반적인 합성곱 층을 뒤집은 것으로, 합성곱 층의 기능을 역순으로 수행함으로써 압축된 정보를 확대하여 원본 이미지를 생성합니다.
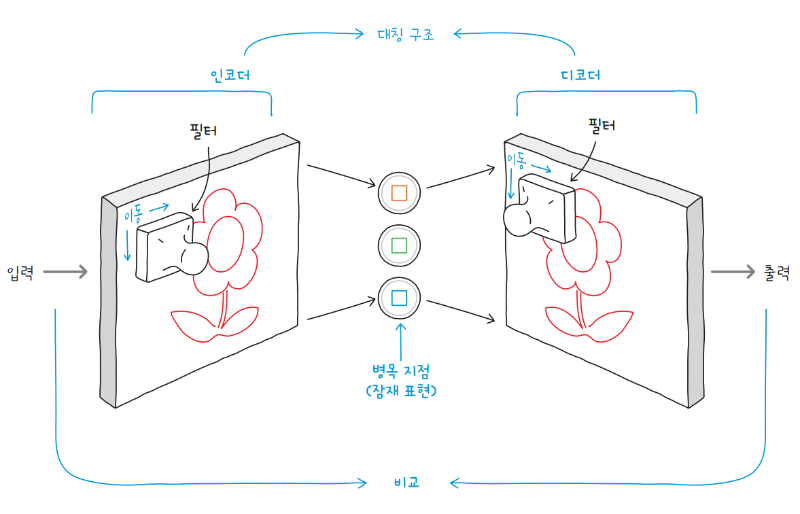
흥미로운 것은 훈련이 끝난 오토인코더에서 디코더만을 떼 내어, 입력 없이도 입력 데이터와 유사한 새로운 데이터를 생성할 수 있다는 점입니다. 입력을 재구성하기 위해 필요한 정보가 잠재 표현에 압축되어 남은 덕분이죠.
실제로 인공지능이 그리는 이미지는 훈련된 합성곱 오토인코더에서 디코더만을 사용해 생성됩니다. 임의의 잠재 표현으로부터 원본과 유사하지만 새로운 이미지를 출력하는 것입니다.
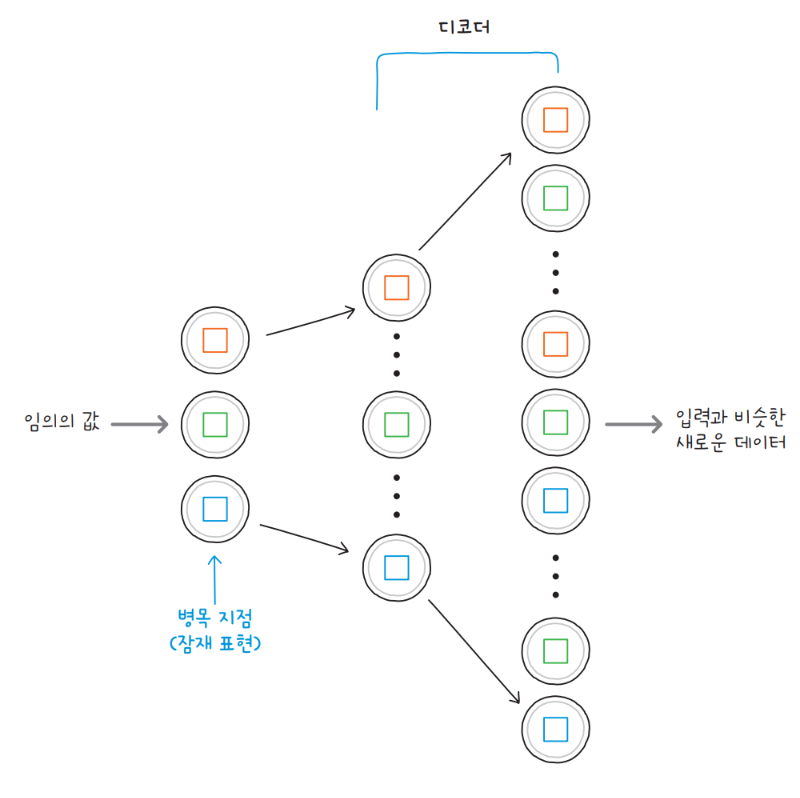
이와 같은 방식으로 오토인코더는 다음과 같은 이미지를 생성할 수 있습니다.

오토인코더는 이미지 생성으로 큰 관심을 받았지만, 오래 지속되지 못했습니다. 곧이어 성능이 더 뛰어난 신경망이 등장했기 때문이죠. 바로 생성적 적대 신경망입니다.
✅생성적 적대 신경망
생성적 적대 신경망Generative Adversarial Network, GAN은 생성자와 판별자가 서로 경쟁하며 훈련하는 독특한 구조입니다. 생성자generator가 전치 합성곱 층을 사용하여 이미지를 생성하고, 판별자discriminator는 합성곱 층을 사용하여 원본 이미지와 생성된 이미지를 구별합니다. 핵심은 원본과 구별할 수 없을 정도로 정교한 이미지를 생성하는 것이죠.
먼저 생성자가 무작위 데이터를 입력으로 받아 가짜 이미지를 생성합니다. 이 이미지를 원본 이미지와 함께 판별자에게 전달하고, 진짜 이미지와 생성자가 만든 가짜 이미지를 구별할 수 있도록 훈련합니다. 판별자의 훈련 목표는 생성자가 만든 가짜 이미지에 속지 않는 것이죠. 판별자는 진짜 이미지와 가짜 이미지를 구별하고, 그 둘이 얼마나 다른지 점수를 매깁니다.
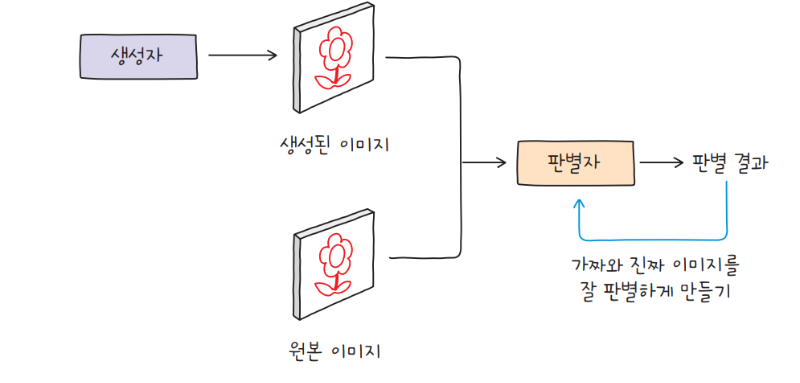
생성자의 훈련 목표는 진짜 이미지와 구별할 수 없을 정도로 정교한 이미지를 생성하여 판별자를 속이는 것입니다. 처음에는 거의 형체를 알아볼 수 없을 정도로 엉망인 이미지를 생성하겠지만, 점차 이미지의 품질을 개선합니다.
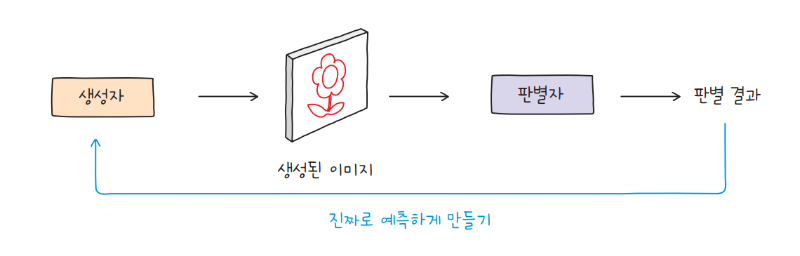
생성자는 판별자를 속이기 위해 더욱 정교한 이미지를 생성하고, 판별자는 속지 않기 위해 진짜 이미지와 가짜 이미지를 구별해 내야 합니다. 따라서 훈련을 통해 생성자와 판별자의 성능은 경쟁적으로 향상됩니다.
충분한 훈련을 거친 후, 신경망에서 생성자만을 떼 내면 이미지 생성에 활용할 수 있습니다. 생성적 적대 신경망을 사용한 모델이 생성한 이미지는 품질이 매우 뛰어날 뿐만 아니라, 원본에 없는 다양한 이미지를 생성해 내기도 합니다. 이를 통해 특정 스타일이나 속성을 띠는 이미지를 생성할 수 있어 다양한 응용 분야에 활용됩니다.
다음은 생성적 적대 신경망의 최신 모델 중 하나인 StyleGAN*으로 만든 이미지입니다. 두 사람은 모두 실존하지 않는 가상의 인물입니다.

이 그림은 「StyleGAN」의 저자인 테로 카라스(Tero Karras)의 동의를 구하고 가져왔습니다.
생성적 적대 모델은 뛰어난 이미지 생성 능력으로 큰 인기를 얻었습니다. 하지만 생성자와 판별자를 균형적으로 경쟁시켜야 하므로 훈련 과정이 까다롭다는 단점이 있죠. 생성자가 너무 우세하면 판별자의 훈련이 잘 이루어지지 않고, 반대로 판별자가 너무 우수하면 생성자의 훈련 경로가 제한되기 때문입니다.
그러던 중 디퓨전 모델이 부상하며 이미지 생성 분야에 혁명이 일어나기 시작했습니다. 현재 이미지 생성 분야에서 가장 뛰어난 성능을 발휘하는 디퓨전 모델이 궁금하시다면 『챗GPT로 대화하는 기술』에서 확인해 보세요.
이전 글 : 어째서 컨테이너가 개발자의 관심사여야 하는가?

최신 콘텐츠