![]() 한빛
한빛
2019-05-24
![]() 16.9K
16.9K
RNN을 사용한 문장 생성
세상에 완벽한 문장은 없어,
완벽한 절망이 없듯이
- 무라카미 하루키, 『바람의 노래를 들어라』
5장과 6장에서는 RNN과 LSTM의 구조와 구현을 자세하게 살펴봤습니다. 바야흐로 우리는 이 개념들을 구현 수준에서 이해하게 된 것이죠. 이번 장에서는 지금까지의 성과(RNN과 LSTM) 가 꽃을 피웁니다. LSTM을 이용해 재미있는 애플리케이션을 구현해볼 것이기 때문이죠. 이번 장에서는 언어 모델을 사용해 ‘문장 생성’을 수행합니다. 구체적으로는 우선 말뭉치를 사용해 학습한 언어 모델을 이용하여 새로운 문장을 만들어냅니다. 그런 다음 개선된 언어 모델 을 이용하여 더 자연스러운 문장을 생성하는 모습을 선보이겠습니다. 여기까지 해보면 ‘AI로 글을 쓰게 한다’라는 개념을 (간단하게라도) 실감할 수 있을 겁니다.
여기서 멈추지 않고 seq2seq라는 새로운 구조의 신경망도 다룹니다. seq2seq란 “(from) sequence to sequence(시계열에서 시계열로)”를 뜻하는 말로, 한 시계열 데이터를 다른 시 계열 데이터로 변환하는 걸 말합니다. 이번 장에서는 RNN 두 개를 연결하는 아주 간단한 방법 으로 seq2seq를 구현해볼 겁니다. 이 seq2seq는 기계 번역, 챗봇, 메일의 자동 답신 등 다양 하게 응용될 수 있습니다. 이 간단하면서 영리하고 강력한 seq2seq를 이해하고 나면 딥러닝의 가능성이 더욱 크게 느껴질 것입니다!
7.1 언어 모델을 사용한 문장 생성
지금까지 여러 장에 걸쳐서 언어 모델을 다뤄왔습니다. 다시 말하지만, 언어 모델은 다양한 애플리케이션에서 활용할 수 있습니다. 대표적인 예로는 기계 번역, 음성 인식, 문장 생성 등이 있죠. 이번 절에서는 언어 모델로 문장을 생성해보려 합니다.
7.1.1 RNN을 사용한 문장 생성의 순서
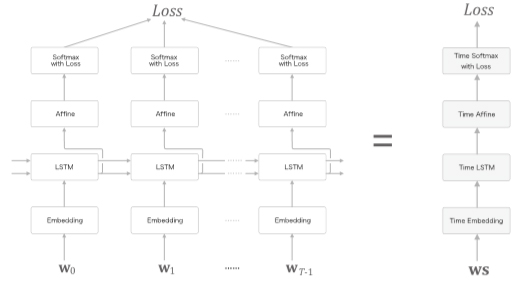
앞 장에서는 LSTM 계층을 이용하여 언어 모델을 구현했는데, 그 모델의 신경망 구성은 [그림 7-1]처럼 생겼었습니다. 그리고 시계열 데이터를 (T개분 만큼) 모아 처리하는 Time LSTM 과 Time Affine 계층 등을 만들었습니다.
이제 언어 모델에게 문장을 생성시키는 순서를 설명해보지요. 이번에도 친숙한 “you say goodbye and I say hello.”라는 말뭉치로 학습한 언어 모델을 예로 생각하겠습니다. 이 학 습된 언어 모델에 “I”라는 단어를 입력으로 주면 어떻게 될까요? 그러면 이 언어 모델은 [그림 7-2]와 같은 확률분포를 출력한다고 합니다.
그림 7-2 언어 모델은 다음에 출현할 단어의 확률분포를 출력한다
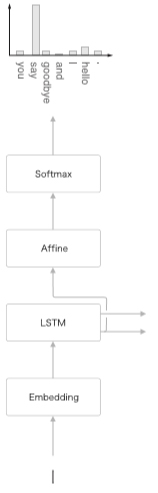
언어 모델은 지금까지 주어된 단어들에서 다음에 출현하는 단어의 확률분포를 출력합니다. [그림 7-2]의 예는 “I”라는 단어를 주었을 때 출력한 확률분포를 보여줍니다. 이 결과를 기초로 다음 단어를 새로 생성하려면 어떻게 해야 할까요?
첫 번째로, 확률이 가장 높은 단어를 선택하는 방법을 떠올릴 수 있을 것입니다. 확률이 가장 높은 단어를 선택할 뿐이므로 결과가 일정하게 정해지는 ‘결정적’인 방법입니다. 또한, ‘확률적’으로 선택하는 방법도 생각할 수 있겠죠. 각 후보 단어의 확률에 맞게 선택하는 것으로, 확률이 높은 단어는 선택되기 쉽고, 확률이 낮은 단어는 선택되기 어려워집니다. 이 방식에서는 선택되는 단어(샘플링 단어)가 매번 다를 수 있습니다.
저는 매번 다른 문장을 생성하도록 하겠습니다. 그 편이 생성되는 문장이 다양해져서 재미있을 겁니다. 그래서 후자의 방법(확률적으로 선택하는 방법)으로 단어를 선택하도록 합니다. 우리의 예로 돌아와서, [그림 7-3]과 같이 “say”라는 단어가 (확률적으로) 선택되었다고 합시다.
그림 7-3 확률분포대로 단어를 하나 샘플링한다.
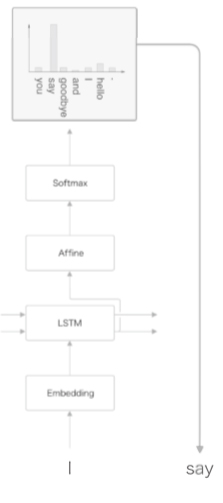
[그림 7-3]은 확률분포로부터 샘플링을 수행한 결과로 “say”가 선택된 경우를 보여줍니다. 실제로 [그림 7-3]의 확률분포에서는 “say”의 확률이 가장 높기 때문에 “say”가 샘플링될 확률 이 가장 높기도 하죠. 다만, 필연적이지는 않고(‘결정적’이 아니고) ‘확률적’으로 결정된다는 점에 주의합시다. 다른 단어들도 해당 단어의 출현 확률에 따라 정해진 비율만큼 샘플링될 가능성이 있다는 뜻입니다.
NOTE. 결정적deterministic이란 (알고리즘의) 결과가 하나로 정해지는 것, 결과가 예측 가능한 것을 말합니다. 예컨대 앞의 예에서 확률이 가장 높은 단어를 선택하도록 하면, 그것은 ‘결정적’인 알고리즘입니다. 한편, 확률적probabilistic인 알고리즘에서는 결과가 확률에 따라 정해집니다. 따라서 선택되는 단어는 실행할 때마다 달라 집니다(혹은 달라질 수 있습니다).
그러면 계속해서 두 번째 단어를 샘플링해봅시다. 이 작업은 앞에서 한 작업을 되풀이하기만 하면 됩니다. 즉, 방금 생성한 단어인 “say”를 언어 모델에 입력하여 다음 단어의 확률분포를 얻습니다. 그런 다음 그 확률분포를 기초로 다음에 출현할 단어를 샘플링하는 것입니다(그림 7-4).
그림 7-4 확률분포 출력과 샘플링을 반복한다.
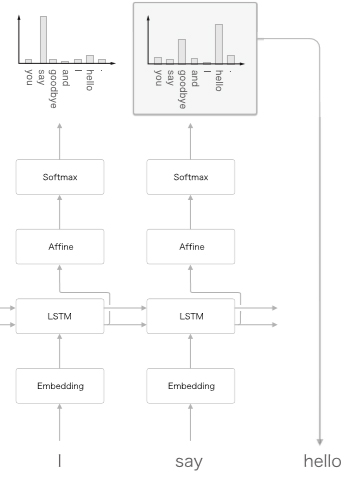
다음은 이 작업을 원하는 만큼 반복합니다(또는 <eos> 같은 종결 기호가 나타날 때까지 반복 합니다). 그러면 새로운 문장을 생성할 수 있습니다. 여기에서 주목할 것은 이렇게 생성한 문장은 훈련 데이터에는 존재하지 않는, 말 그대로 새로 생성된 문장이라는 것입니다. 왜냐하면 언어 모델은 훈련 데이터를 암기한 것이 아니라, 훈련 데이터에서 사용된 단어의 정렬 패턴을 학습한 것이기 때문이죠. 만약 언어 모델이 말뭉치로부터 단어의 출현 패턴을 올바르게 학습할 수 있다면, 그 모델이 새로 생성하는 문장은 우리 인간에게도 자연스럽고 의미가 통하는 문장일 것으로 기대할 수 있습니다.

![]() 0
0




댓글