


이책은 생각보다 책 두깨가 엄청 두껍지는 않치만
데이터 과학에 필요한 모든 내용을 책에서 부족함 없이 다루고 있다.
1. 데이터 분석 기초
2. 파이썬에 대한 문법 및 데이터 처리방법
3. 머신러닝에 대한 이론과 학습방법
4. 컴퓨터 메모리 구조까지 다루고 있다.
친절히 역자의 소스 코드를 github에서 제공하고있어서 실행하기도 편했다.
파이썬 학습
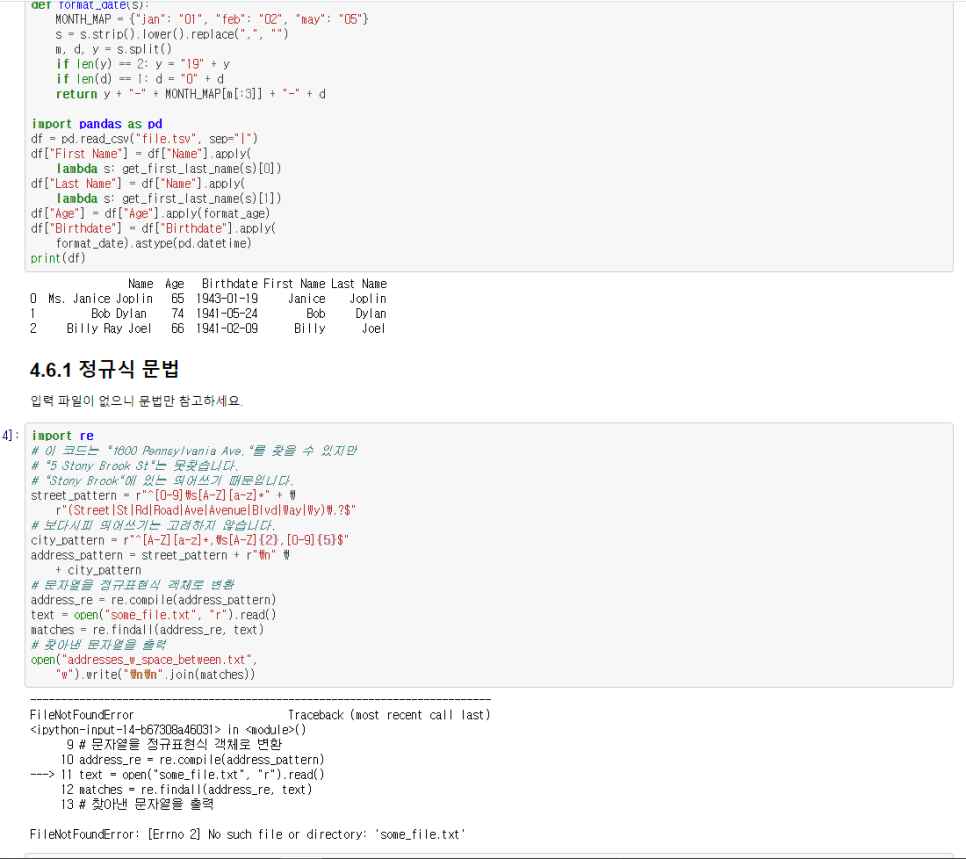
파이썬 소스코드
파이썬에 대해서는 별도로 다른책을 공부하지 않아도 이책만 학습해도 편안하게 공부를 학습할수있을 정도의 내용을 다루고 있다.
머신러닝
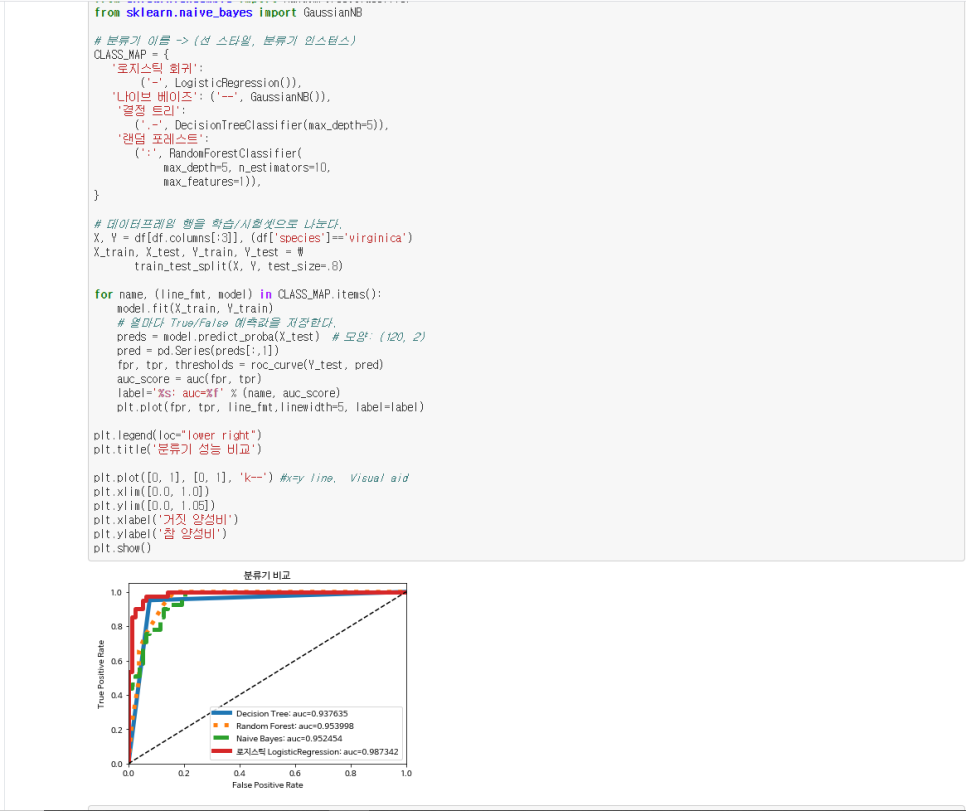
데이터를 통해 머신러닝 학습사례
전반적으로 책을 쭉 따라가다 보면 어느새 머신러닝으로 데이터를 분석하는 단계 까지 학습할수 있다.
자연어 처리
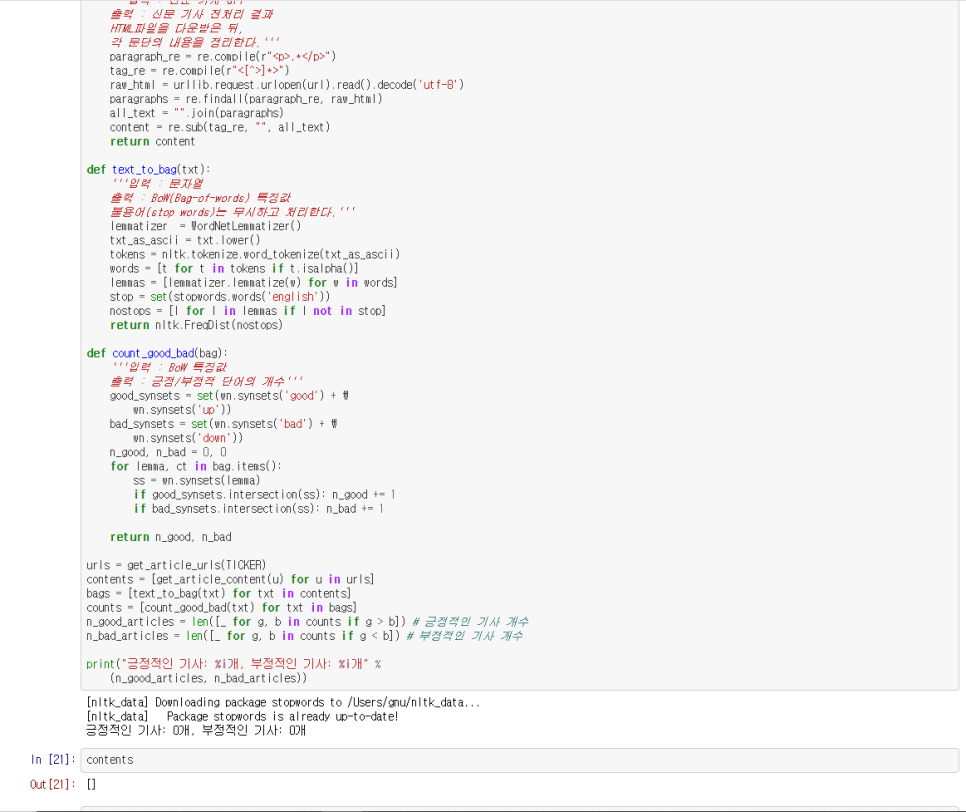
자연어 처리
자연어 처리를 통해 긍정적인 기사와 부정적인 기사를 분류하는 내용이 소개되어있다.
머신러닝 고급 분류방법
다양한사례로 데이터 분석한 차트
여러 머신러닝 분류방법으로 데이터를 추출해볼수있었으며, 여러 분률방법을 통해 데이터 에 따라 어떤 분류가 적합한지 실행해 볼수 있었다.
요약
전반적으로 학습후에는 데이터 과학에 필요한 어느정도의 필수요소의 기술과 학습을 충분히 할수가 있었으며, 책이 400페이지가 넘는 분량으로 , 생각보다 내용이 많았다.
실무에 필요한 내용으로 다루고있고, 이론과 실습이 적절하여 어려운 내용을 다룸에도 전혀 지루하지않고, 재미있었다.
말그대로 데이터 과학에 입문하기에는 좋은책이라 생각한다.








