개요
본 리뷰는 한빛미디어 출판사 "자연어처리 딥러닝 캠프(김기현 저)"를 읽고 얻은 지식을 정리한 글입니다.
인공지능이 논문을 학습한다면
수학에 뿌리를 둔 통계학. 통계학에 뿌리를 둔 머신러닝. 머신러닝에 뿌리를 둔 딥러닝. 그리고 딥러닝에 뿌리를 둔 NLP가 있다. 자연언어처리라고도 불리는 NLP는 인공지능 기술 중 하나로 기계로 하여금 인간의 언어를 이해할 수 있게 만드는 기술이다. 이 기술이 실현된다면 마치 사람으로 따지면 통역가와 같이 다국어 간의 컴퓨터, 기계를 통한 번역이 가능해진다. 뿐만 아니라 문서 자동분류, 챗봇 등 다양한 응용분야으로의 적용도 가능해진다.
자연 언어 처리(Natural language processing)
자연어 처리(自然語處理) 또는 자연 언어 처리(自然言語處理)는 인간의 언어 현상을 컴퓨터와 같은 기계를 이용해서 모사 할수 있도록 연구하고 이를 구현하는 인공지능의 주요 분야 중 하나다. 자연 언어 처리는 연구 대상이 언어 이기 때문에 당연하게도 언어 자체를 연구하는 언어학과 언어 현상의 내적 기재를 탐구하는 언어 인지 과학과 연관이 깊다. 구현을 위해 수학적 통계적 도구를 많이 활용하며 특히 기계학습 도구를 많이 사용하는 대표적인 분야이다. 정보검색, QA 시스템, 문서 자동 분류, 신문기사 클러스터링, 대화형 Agent 등 다양한 응용이 이루어 지고 있다. - 위키백과 -
이 자체로도 충분히 전도 유망한 기술이지만 필자가 딥러닝 기술 중 NLP에 가장 관심이 많은 이유는 다른데에 있다. 바로 소제목에서 명시한 바와 같이 논문을 학습하게 될 가능성 때문이다.
필자가 보기에 논문은 그야말로 딥러닝의 언어이다. Review 논문은 마치 Graph Theory를 활용하여 구성하기에 딱 좋은 형태이며 학문이 발전해 온 전체 목차를 구성하기 좋고, 대부분 논문의 Abstract에는 Review 논문의 흐름 중 어느 카테고리에 붙어야 어울리는지 힌트를 제공한다. 또 내부 지식은 대부분 귀무가설과 검증에 대한 시행착오가 담겨져 있어 통계학을 원류로 하는 현 딥러닝 모델이 인식하기에 적합한 지식 구조로 이루어져 있다.
딥러닝이 핫이슈이긴 해도 현재까지는 적용되는 범위가 한정되어있는데 주로 이미지, 음성, 영상 인식 등에 국한되어있다. 이 분야들의 공통점은 자연 그대로가 아닌 1차 가공을 거친 데이터를 피처로 활용한다는 점이다. 신호처리 등 그간의 학문분야에서 심도 있게 연구되어 온 축적된 지식이 있기에 딥러닝 모델이 인식하기 좋은 형태로 변환하거나 특징을 추출, 선택, 변환할 수 있는 것이다. (보다 자세히 다룬 내용은 필자의 블로그 “통계학 vs 컴퓨터공학, 멋대로 써보는 Data Science 미래에 대한 소고(小考)-세상 모든 논문들을 딥러닝이 이해할 수 있게” 부분을 참고하시기 바란다.)
이런 측면에서 볼 때 NLP는 목적 그 자체가 될 수도 있으나, 세상의 거의 모든 분야의 데이터를 딥러닝이 이해하기 쉽고 좋은 성능을 낼 수 있도록 Feature생성 혹은 전처리 역할을 담당하는 일종의 중간 Layer로 활용될 가능성이 크지 않을까 생각한다. DQN 등 Reinforcement Learning과 결합하여 논문을 이해하고 구현체를 만들 수 있는 날이 온다면 세상은 대 격변을 맞을 것이라 생각한다. 때문에 필자는 NLP를 활용하여 논문을 학습할 수 있는 모델을 설계하거나 이를 뒷받침하는 연구를 하고 싶다는 꿈이 있다.
NLP를 배우는데 있어 본 도서의 장점
NLP 기술이 왜 중요한지 그리고 미래에 얼마나 유망한지 위 장에서 간단하게 언급하였다. 그렇다면 NLP 기술은 어떻게 익혀야 할까? 적어도 한국어와 관련된 자연어 처리라면 이 책이 해답 중에 하나라고 말하고 싶다. 그간 시중에 출간된 NLP 서적은 흔했지만 깊이가 너무 얕았다. 이와 관련하여 본 도서가 가지는 특출난 장점이 몇가지 있어서 소개해 본다.
-
일단, 한국어 NLP를 다룬다.
-
한국어에는 다른 언어에 비해 다음과 같이 자연어 처리를 어렵게 만드는 요소가 있다.
- 교착어 : 접사가 붙어 의미와 문법적 기능이 정해진다. (예: 잡히시었겠더라)
- 띄어쓰기 : 표준이 계속 변한다.
- 평서문과 의문문 : 동일한 문장구조를 가진다.
- 주어생략 : 명사를 중요시하는 영어와는 달리 동사를 중요시한다.
-
한자(漢字) 기반의 언어 : 표음문자의 특징인 중의성 문제(예: 건널
제, 끌제, 제목제)
- 대부분의 장에서 영어 기반의 NLP 기술과 수학적 근간을 설명한 후 한글에 적용해보며 특수성을 언급하고 해결책을 제시한다.
-
깊이가 있다. (재미는 입문서급이다.)
- NLP 초보자라면 언어모델링도 쉽지않은데 이 책은 그 이상의 심화주제를 소개한다.
-
듀얼리티, 전이학습, NMT시스템 구축 등은 그간 https://arxiv.org에서 접하면서 이해가 까다로웠던 부분인데 비교적 최신 기술을 학습하고 그 결과를 공유해주려는 저자의 배려가 돋보였다. 이런 심화 내용에 대한 개념을 잡을 수 있었던 것이 필자에게는 가장 큰 소득이었다.
-
다양한 전처리 기법 및 정규표현식의 소개
- 그간의 전처리에서 겪었던 시행착오를 한방에 깔끔하게 정리해주었다.
-
아래 그림과 같이 알기쉬운 도식을 통해 정규표현식 또한 엑기스를 뽑아 전수해준다.

-
기계번역을 정면돌파한다.
- 그간 시중의 NLP 서적이 마음에 안들었던 이유는 크게 한국어, 번역 두 부분이었다.
- 특히 기계번역은 난이도가 높아 다른 서적에서 잘 언급하지 않는데 이 책은 과감히 기계번역을 시도한다.
-
수학을 정면돌파한다.
- 확률변수부터 MLE, MSE까지 직관적으로 설명한다. 문제를 푸는 수학이 아닌 어디에 왜 써야하는지의 관점으로 접근한다.
-
아래 그림은 몬테카를로 샘플링에 관한 설명이다. 기본 수학을 떼신 분이라면 꽤 깔끔하게 직관적으로 설명하는 저자의 능력 덕분에 그간 복잡하게 엉켜있던 수학의 개념이 쉽게 정리되는 것을 느끼실 수 있을 것이다.

-
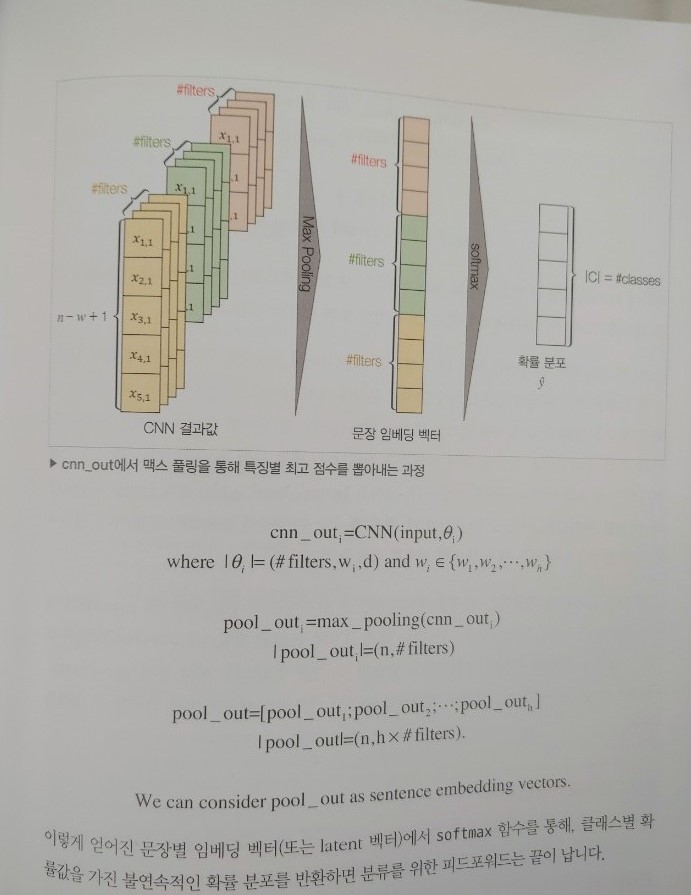
아래 그림은 벡터유사도에 관한 설명이다. 쉽게 설명한다는 핑계로 수식을 열거하지 않는 책들이 많은데 그렇게 쉽게 얻은 지식은 희미한 개념으로만 남을 뿐 다른 분야에 적용할 때 그 한계를 드러내기 마련이다. 가급적 간명한 설명을 통해 하나도 근본 원리를 놓치지 않으려는 저자의 시도가 마음에 들었다.

-
기타
- 그 외에도 패스트캠퍼스의 검증된 강의를 기반으로 한다는 점
- Pytorch와 친숙해질 기회라는 점
-
저자의 GitHub에 완성도 높은 구현체가 공개되어 있다는 점이 장점이라고 할 수 있겠다.
내용의 깊이, 구성, 저자의 열정 뭐 하나 떨어지는 구석없이 잘 만들어진 책이라는 생각이 들었다.
누가 읽어야 하는가?
책의 구성 및 요약
이 책은 크게 네 부분으로 구성되며, 각 장에서 다루는 내용을 요약해 보았다.
-
1. NLP 학습을 위한 준비운동(0 ~ 3장)
- 딥러닝 및 NLP의 개요, 기술의 발전과정
- 기초수학에 대한 내공쌓기
- 개발실습환경 구축 및 Pytorch 기본문법 학습
-
2. NLP 기초체력 다지기(4 ~ 7장)
- 정규표현식 등 전처리의 다양한 기술 학습
- 원핫인코딩, TF-IDF, 벡터유사도, 중의성 해소 등 NLP 입문서 수준의 주요 개념 정리
- word2vec 등 단어임베딩 및 시퀀스 모델링, 텍스트 분류 등 중급 내공 쌓기
-
3. 기계번역(9장 ~ 11장)
- SRILM, NNLM 등 언어모델의 활용법 및 n-gram실습
- seq2seq, 어텐션 등을 활용한 신경망 기계번역
- 다국어 신경망 및 트랜스 포머 등 심화주제 소개
-
4. __심화주제(12장 ~ 15장)
- 강화학습 적용 및 자연어 생성
- 듀얼리티, NMT 시스템 구축, 전이학습 등 최신기술 소개
요약하며…
언제나 그렇듯이 이런 양서는 왜 늦게 나오는지 모르겠다. 그동안 다른책에 낭비된 시간이 아깝기 때문일까. 꽤 어려운 주제들을 언급하고 있는데 반해 솔직히 꽤 재미있게 읽었다. 물론 정독하고 수식까지 음미하려면 꽤 많은 시간이 소요될 것 같다. 책을 읽으며 가장 인상 깊었던 점은 수준높은 주제를, 저자가 그동안 공부하고 노력하고 연구했던 지식들 전부를, 어떻게든 한정된 지면안에 간결하게 쏟고자하는 노력이 느껴졌다는 점이다. 수학, 통계학 등 기초 체력이 잘 다져진 분들에게는 NLP 기술이 잘 집대성된 양서를 만났다는 느낌이 들 것이다.
아쉬웠던 점이 있다면 그런 저자의 열정때문에 설명에 다소 축약이 많아 기초 내공이 약하거나 입문자이신 분들한테는 실습 환경 하나 구축하기 조차 벅차다는 생각이 드실 것 같다. 더불어 수식으로 열거된 설명 부분은 좀 더 자세하고 쉽게 설명이 되어있다면 교과서로 쓰여도 무난하지 않을까 하는 약간의 아쉬움은 들었다. 하지만 이런 아쉬운 점은 전체 장점 대비 극히 작은 영역이기에 별로 중요하지 않다.
<한빛미디어 출판사>
믿고보는 “한빛미디어 출판사”. IT분야에서 독보적인 양질의 도서를 출판하는 회사입니다. “나는 프로그래머다” 팟캐스트 후원, DevGround2019 행사, 리뷰어 모집, 다양한 학습 지원 등 다양한 분야에서 사회에 공헌하는 개발자와 공생하는 업체입니다. IT분야에 관심있으시다면 한빛미디어의 책으로 후회없는 출발을 하실 수 있습니다.
한빛미디어 바로가기

![[상세이미지]김기현의 자연어 처리 딥러닝 캠프(파이토치 편)_940.jpg](https://www.hanbit.co.kr/data/editor/20190621103809_nlhcpcbe.jpg)