제공 :
한빛 네트워크
저자 : DC Denison
역자 : 전희원(고감자) |
http://freesearch.pe.kr
원문 :
Getting Google to notice your ebook
이제 구글이 그들의
이북 스토어(ebook store)를 오픈했으니 남은 건 출판업자나 저자들이 약간의 SEO(search engine optimization, 검색 엔진 최적화)를 배워볼 때가 된 거 같다.
만일 여러분들이 신발이나 핸드폰을 온라인으로 판매한다면 이미 SEO에 친숙할 것인데, 친숙하지 않다면 사업이 그다지 성공적이지 않았을 것이다.
지금까지 출판업자들은 특별한 환경에서 살아왔다(구글보다 더 특수했던 아마존이나 반즈앤노블스가 있지만). 그러나 구글 이북스토어(Google eBookstore)는 출판업자들이 SEO에 신경써야 되는 이유를 만들어 줬다.
왜냐하면 구글이 여러분의 책을 찾을 수 있다면 그 사실은 여러분의 책을 팔 수 있다는 것을 의미하기 때문이다. 물론 그 판매의 장이 되는 곳은 온라인 이북스토어 뿐만 아니라 안드로이드 플랫폼이나 애플 앱일 수 도 있으며, 독립적인 북스토어 파트너사가 될 수도 있다.
그러나 구글이 여러분의 책을 인식하게 만드는게 말처럼 쉽지만은 않다.
나는 이 사실을 “
Ebook Publishers to Watch: 2011” 라는 테스트 이북을 올려 두었을 때 알았다. 아마존에 올려 두었으며 문서는
Scribd에 업로드를 해두었다. 장바구니와 함께 가이드 웹 사이트를 만들어 두었다. 특별한 홍보를 하지 않았음에도 불구하고 꽤 빠른 시간에 나쁘지 않게 팔렸다.
그러나 구글에서 거의 찾아보기 힘들다는 사실을 눈치챘다.
아니, 그것보다 더 심한건. 내 이북이 직접 구글 서치 박스에 정확한 이름을 입력해 검색을 했을 때 조차도 상위에 랭크되지 않는다는 사실이였다.
TeleRead에 있는 책의 언급에서 크게 한방 맞았는데, 그건 순간 내 정신이 확 들게 만들었다. 그래서 일단 생각하기 사작했다. “내가 SEO 기법을 무시한게 있었던가?” “키워드를 선택해야 하나?” “챕터의 제목에 대해서 최적화가 필요한가?” “구글이나 빙 검색을 위해 사이트맵(sitemap)을 넣어야 할까?” “예시가 될 만한 최근 이북 저자가 있을까?”
구글이 책에 대해서 가지고 있는 관점
구글 이북스토어 이전에 있었던 소식에서 구글이 책을 굉장히 심각하게 여긴다는 사실을 알았다. 나는 이 소식을 세르게이 브린이 지난해 기자회견 이후 나눴던 대화에서 직접 들었다. 그는 구글의 공동 창업자인 레리 페이지가 창업 초기부터 지금까지 책을 스캐닝하고 색인하는데 많은 관심을 가져왔다는 사실을 알려주었다. 뭐 이야기가 빗나가 그의 신발에 대한 간단한 이야기를 하기도 했지만 말이다...
최근에 구글 북 서치 품질팀의 수석 소프트웨어 엔지니어인 매튜 그래이(Matthew Gray)와 대화를 나눴을 때, 그는 구글의 상위결과에 이북이나 책들이 노출되게 하는데 다시 관심을 보이고 있었다.
그는 “우리의 목표는 접근 가능하며 유용한 모든 세상의 정보들을 만드는 것입니다. 그리고 세상의 많은 정보들이 책에 있다고 믿고 있죠”라고 말했다. “따라서, 정보가 사용 가능하게 만드는게 우리에게 중요한 일입니다. 만일 당신이 어떤 병이나 여행 목적지에 대해서 알고 싶어 한다면 가장 좋은 정보가 책에 있을 가능성이 높습니다.”
2005년 이래로 35,000명의 출판업자들이 가입한
구글 프리 북 파트너 프로그램(Google Books Partner Program)을 이야기 하자면 그곳에 가입한 출판업자들의 모든 책의 내용들은 색인되고 검색엔진의 결과에 노출되었는데, 이로인해 인터넷 사용자들은 검색 결과 근처에 있는 책의 콘텐츠 중에 20페이지 정도를 살펴볼 수 있게 되었다. 물론 어느정도 살펴볼 수 있는지에 대한 결정은 출판업자들이 하지만 말이다. 애매한 저작권을 가진 책들에 대해서는 구글이 제안한 타협안을 따르게 되며 검색 결과 근처의 콘텐츠에 대해서 짧은 내용만을 노출한다.
책들은 이제 검색 서비스에서 ‘발견될만한 것’들이 되었다. 예를 들어 2008년 말 금융 붕괴의 시기에 인터넷 사용자들은 “경제추락(economic crash)”이라는 검색어를 검색엔진이 입력했고, “대폭락 1929(The Great Crash of 1929)”이라는 제목의 존 케네스 갤브레이스가 1955년 첫 출간한 책을 발견할 수 있었다. 이 책은 호그턴 미프린 하코트라는 출판업자의 도서목록에 있던 책중에 하나였다. 갤브레이스의 책은 사람들의 관심에서 사라질 운명에 처해졌으나, 검색 쿼리가 책의 내용에 잘 부합이 되어 구글을 통해 다시 사람들에게 보여질 수 있게 되었다.
메타데이터와 마켓 시그널
그럼 신간 서적과 이북의 경우 어떤가? 구글 이북스토어의 웹 검색 입력창 아래 나타나는 검색 결과 페이지들이 나오는데, 이때 어떻게 구글은 새로운 제목의 책이라는 것을 1,500만권의 스캔된 책들중에서 판별하는 것일까?
이건 구글 북 프로젝트에 참여하고 있는 그레이(Gray)나 다른 구글 엔지니어들에게는 하나의 도전이 되는데, 왜냐하면 웹 페이지의 가치를 측정하는 구글의 알고리즘(다른 페이지들이 명시한 링크 개수를 기반으로 한)이 책이나 이북에 대해서는 전혀 작동을 안하기 때문이다. 물론 구글 북스(Google Books)에 있는 특정 책에 대해서 링크를 걸 수는 있다(여기 갤브레이스 책 링크를 넣어본다). 하지만 대부분의 사람들은 책이나 이북들의 콘텐츠에 링크를 걸지는 않는다. 따라서 링크는 책의 가치를 측정하는 수단이 될 수 없는 것이다.
이북스토어의 런칭 전에 그레이와의 대담이 있었으나 접근 방법이 달라지지 않았다는 것을 확인 할 수 있었다 .
구글이 적용한 한가지 전략은 기존 출판계의 ‘풍부한 기존의 메타데이터’와 친해지는 것이였다. 저자 추천사, 부제목, 줄거리, 리뷰 그리고 저자 약력 등의 리소스들이 해당 책과 이북의 정보를 반영하고 있다는 것에 대해서 인지하기 시작했다고 그레이가 언급하였다.
현재, ONIX라는 파일 포맷으로 만들어진 메다데이터들이 책과 함께 제공된다. ONIX라는 파일 포맷은 “ONline Information eXchange”의 약자로 XML을 기반으로 한 200개가 넘는 데이터 요소를 포함하는 표준이다(이곳에는 저자명과 책 제목, 리뷰, 저자 사진 그리고 개요 등이 포함되어 있다). 구글은 출판업자들에게 ONIX 피드를 제공할 수 있게 허용하고 있다고 그레이는 말했다.
또한 구글은 그레이가 언급했던 것처럼 “마켓 시그널(market signals:)”-- 얼마나 자주 책이 재인쇄 되며, 웹 검색이 수행되며, 최근 책 세일이 언제였는지와, 이 책을 소장하고 있는 도서관이 얼마나 되는지의 정보를 포함하는--을 살펴본다.
구글의 북 서치 알고리즘은 100개가 넘는 시그널(signals)을 사용하고 있으며 그 시그널들은 계속 변화한다. “구글 북스에서 상위에 랭크되기 위해서 할 수 있는 가장 빠른 방법은 진짜 좋은 책을 쓰는거죠.”라고 그레이는 말했다.
그리고 일단 시그널들이 북 서치의 특정 타겟을 지명하고 있으면 구글 북스는 큰 크기의 책표지와 제목으로 확실하게 보여준다. 예를 들어 만일 여러분이 말콤 그레드웰의 “티핑 포인트(The Tipping Point)”를 찾고자 하는 검색어를 입력했다고 가정한다면, 검색엔진은 나머지 대여섯개의 엇비슷한 제목의 다른 책들과는 다르게 페이지의 첫 목록에 “티핑 포인트”를 확실하게 보여줄 것이다.
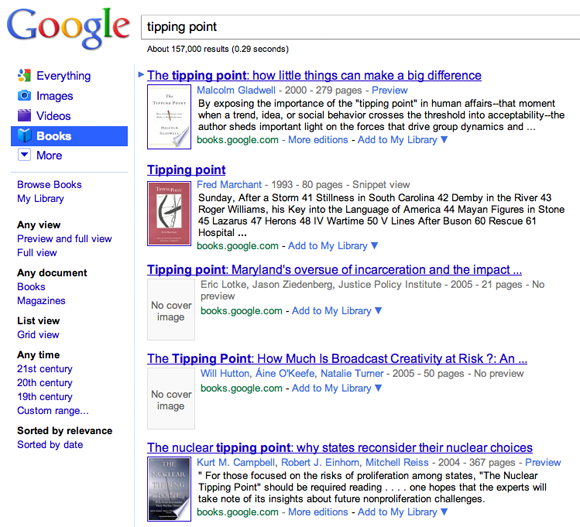
구글은 검색 결과의 상위에 확실한 결과들을 올리기 위해 시그널을 사용한다. 이 결과에서는 구글은 “tipping point”라는 검색어가 같은 제목의 다른 책들보다 사용자가 말콤 글레드웰의 책을 찾길 원한다는 것으로 가정한다.
구글이 당신의 책을 인지하기 위한 세 가지 좋은 예제들
시그널이 동작하긴 하지만, 구글이 이북이나 책들을 인지할 확률을 높이기 위해 저자나 출판업자들이 따르면 좋을 몇 가지 좋은 예제가 있다고 그레이는 말했다.
1. 챕터 제목이나 책 제목에 서술형을 사용하라 -- 이런 “깔금한 정보” 선호 접근 방법은 구글로 하여금 책에서 관련 콘텐츠를 찾기 쉽게 하며, 다른 구글 검색 서비스에서 콘텐츠를 제공하기 위한 동기를 유발하게 된다.
예를 들어, 책에 웹의 역사에 대해 서술하고 있는 챕터를 포함한 인터넷 관련 서적이 있다고 한다면, 단순히 “역사”라는 단어를 제목에 사용하는 것보다는 “웹의 역사”라는 제목을 사용하는 것이 훨씬 낫다는 것이다.
“우리는 우리가 할 수 있는만큼 최선을 다할 것입니다. 그러나 좀 더 완전한 챕터 제목이 우리를 도와줄 수 있겠죠”라고 말했다.
2. 책 외부에서 좋은 내용의 콘텐츠를 만들어라 -- 당신이 책 외부에 만든 콘텐츠도 좀 다르게 상황을 만든다. 그레이가 베스트셀러인 스티븐 레빗의 “괴짜경제학(Freakonomics)”이란 책을 예로 들었는데, 이 단어를 검색해보면 첫 번째 검색 결과가 책이 아닌 뉴욕타임즈의 “괴짜 경제학 블로그(Freakonomics Blog)”가 나오며 그 다음에 책의 웹 사이트가 나오며 이후엔 아마존의 결과가 나온다는 이야기를 했다.
아마도 블로그 갱신 빈도, 뉴욕 타임즈의 권위 그리고 타임즈의 괴짜 경제학 블로그 글에 유입되는 인링크(inlink)들의 숫자가 사이트 자체의 랭킹을 진짜 책보다 더 올려준 결과를 야기시키지 않았다 예상해 본다.
그럼에도 불구하고, 컬럼의 탁월함이 구글내에서의 책의 랭킹을 올려줬다는 사실은 부정할 수 없다. 책 콘텐츠를 증대하기 위해 웹을 사용하는 출판업자들이 많아지면 많아질수록 이런 종류의 시너지 효과는 일반화 되지 않을까 한다. “책과 이외의 콘텐츠 사이의 경계가 희미해지는 상황은 제가 예상했던 그 이상이더라고요.”라고 그레이는 말했다.
3. 책 표지의 문제 -- 구글이 발견한 한가지 중요한 메타데이터 속성은 책의 표지라고 그레이가 아이러니한 표정을 지으면서 말했다.
“책표지는 사실 굉장히 풍부한 메타데이터 자체입니다.”라고 말했다. “사람들은 표지 스타일을 책의 저자나, 어떤 시리즈물로 연결시킵니다. 결국 그들은 표지에 반응하게 되는 거죠. 그들은 표지를 인지하고 이렇게 말합니다. ‘저게 내가 찾던 책이군..’”
그레이는 책이나 이북 출판업자들에게 표지에 신경 쓰라고 조언한다. “우리는 깨달았습니다. 사람들은 사실 책표지를 가지고 판단하더군요.”하고 말했다.




댓글