오랜만에 굉장히 이론의 비중이 높은 신간 데이터 과학 책을 만났다. 읽기 쉽게 쓰여진 책들도 좋지만 개인적으로 이렇게 글이 빡빡하고 넓은 범위의 내용을 꼼꼼하게 써놓은 책을 더 좋아한다. 많은 내용이 담겨 있기 때문에 하나의 개념에 대해 깊게 들어가는 책은 아니지만 다양한 영역에서의 데이터 과학에 대해 학습해 볼 수 있는 좋은 책이었다. 입문서로써도 괜찮지 않을까 생각되는 책이다만 밀도 높은 책을 싫어한다면 조금 경기를 일으킬 수는 있겠다.

저자 소개를 꼭 해야겠다. Matt Taddy. 아마존의 부사장으로 시카고 경영대학원에서 통계학 교수로 재직하면서 본인만의 데이터 과학 커리큘럼을 개발했다고 한다. 그 내용이 온전히 이 책에 담겨 있을 것을 기대하고 보니 왠지 더 믿음이 갔다. 어쩐지 책을 보는데 수업을 듣는 느낌을 받더라니...

이 책이 경영대학원의 데이터 과학 수업을 위한 커리큘럼을 만든 교수이자 한 회사의 대표가 저술한 것임을 알고 읽으면 확실히 다른 개발 서적과는 조금 다른 관점에서 쓴 책임을 알 수 있다. 저자는 생각하는 대상 독자로 단순히 개발자들만을 위해 쓰지 않았다. 더 크게, "과학자" 를 대상으로 했으며, 그 안에는 컴퓨터 과학자 뿐만 아니라 생물학, 물리학, 기상학, 경제학 등 여러 분야를 포함한다. 최소한의 프로그래밍 경험만 있으면 읽을 수 있는 수준으로 작성되었으며 데이터 과학에 대한 비전문가들도 경력 전환을 위해 쉽게 학습할 수 있도록 하기 위해 노력했다고 한다.

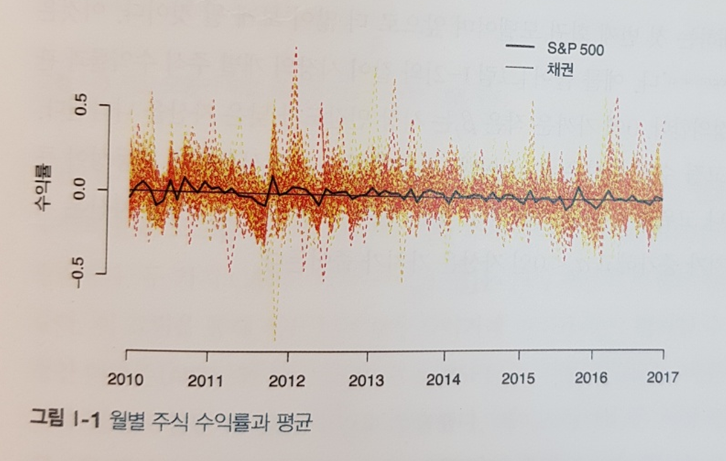
경영대학원 교수님 출신 답게 시작은 미국의 대표적인 지수 S&P500 에 대한 내용을 보여주면서 시작한다. 이 책을 계속 따라가다보면 다양한 데이터를 직접 다뤄보고 시각화도 해보면서 많은 인사이트를 얻을 수 있을 것 같다.

초반의 내용은 통계학의 내용이 주를 이룬다. 학생 시절에 확률, 통계 등을 잘 공부했다면 아주 쉽고 재밌게 넘어갈 수 있겠지만, 역시 언제봐도 헷갈리고 어렵다. 처음에 공부를 해서 잘 이해했다고 생각한 뒤 프로그래밍만 주구장창 하다보면 언제부턴가 깊은 개념은 잊고 단순히 사용 방법과 결과만 알고 쓰게 되는데, 이런 이론서들을 끼고 다니면서 복습하는 습관을 가진다면 정말 어려운 문제를 만났을 때 스스로 문제를 해결하는 능력을 많이 키울 수 있게 되지 않을까.
경제학자 답게 확률에 대한 내용들을 단순히 수학적인 설명만으로 하지 않고 경제학에서 사용하는 용어들을 적절하게 섞어서 표현한다. 확률과 비용 그리고 분류가 한 소단원의 제목으로 들어있는 것은 확실히 개발자 입장에서 새롭다.

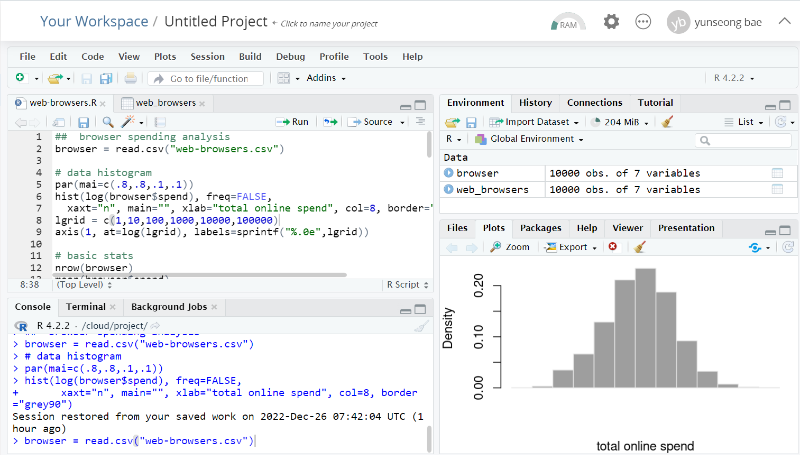
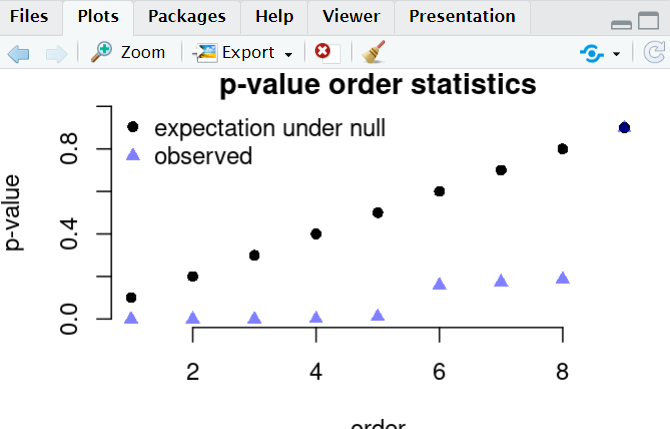
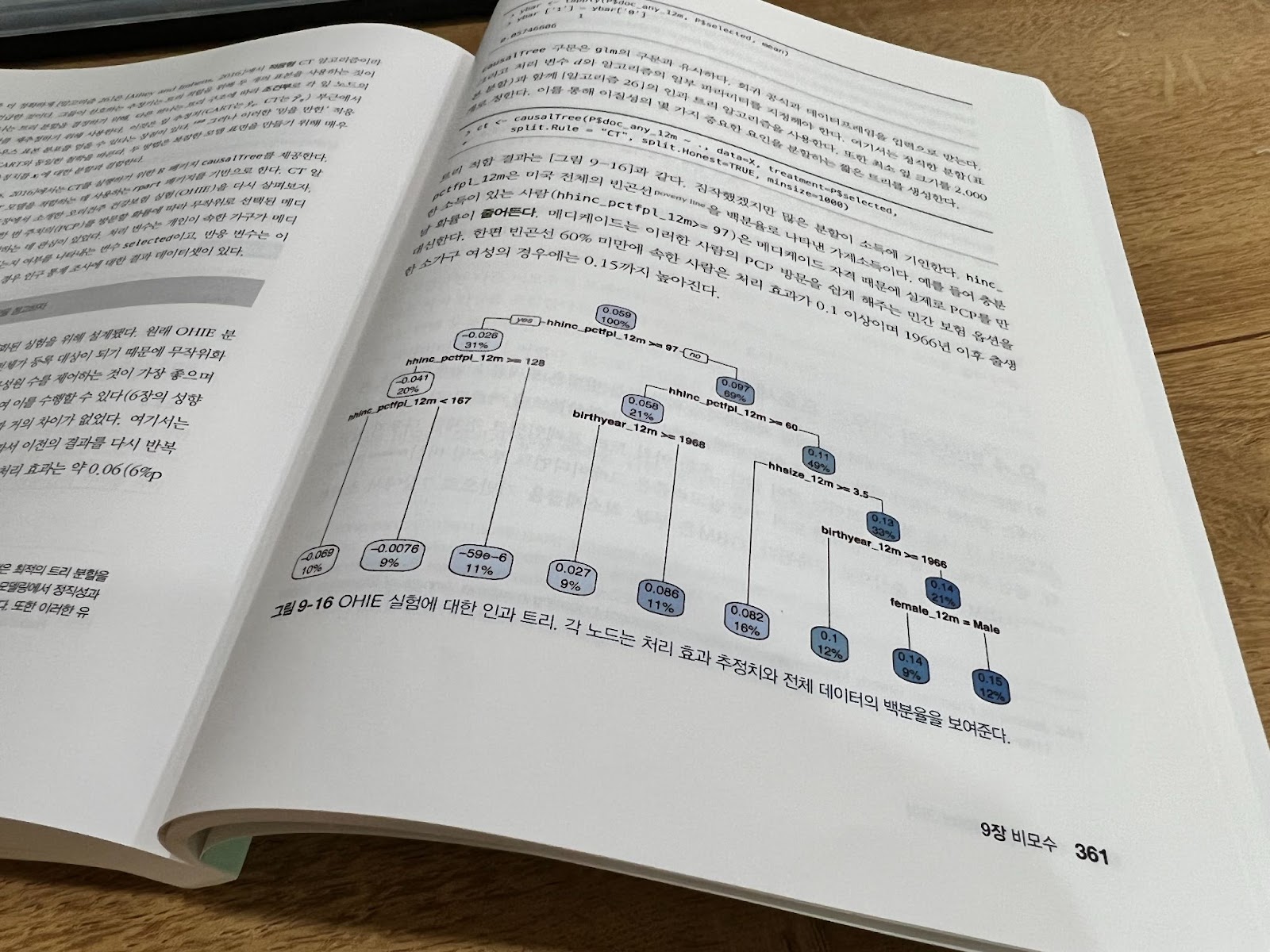
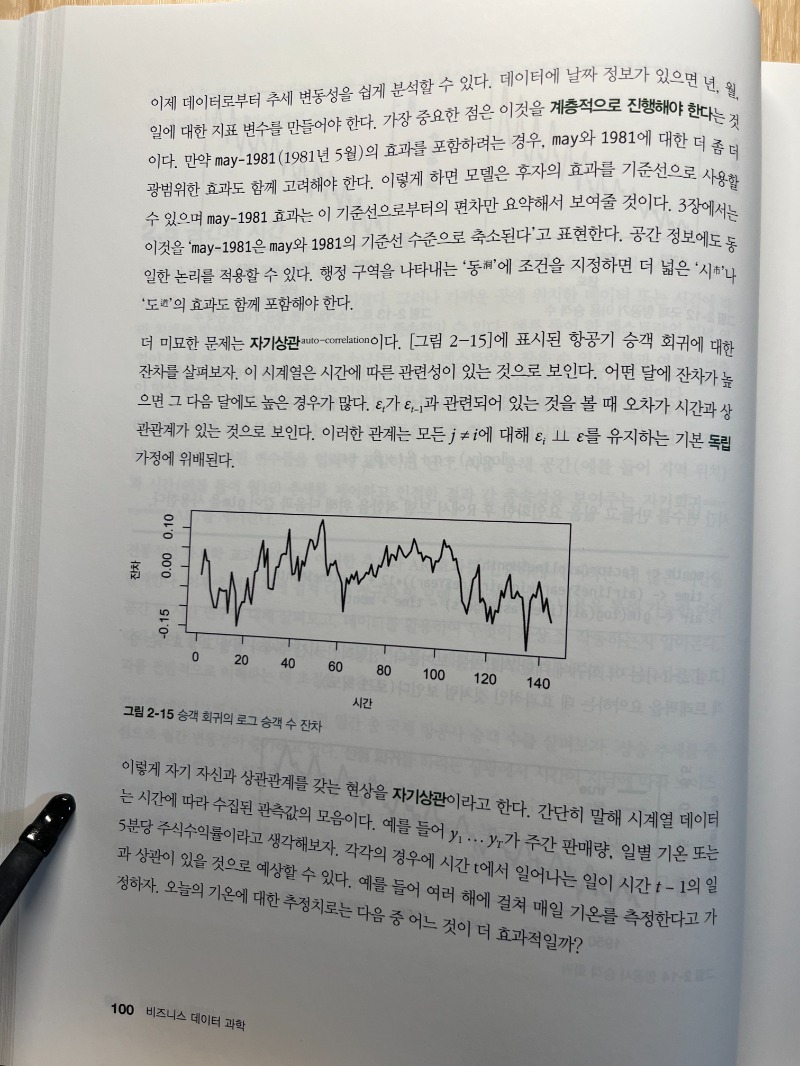
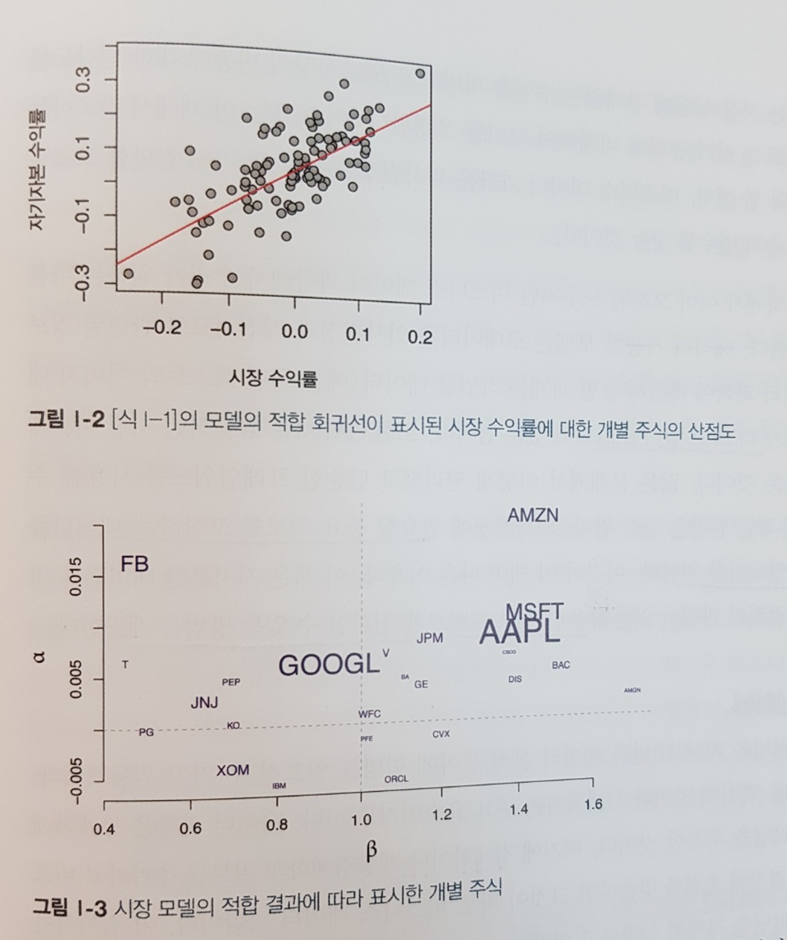
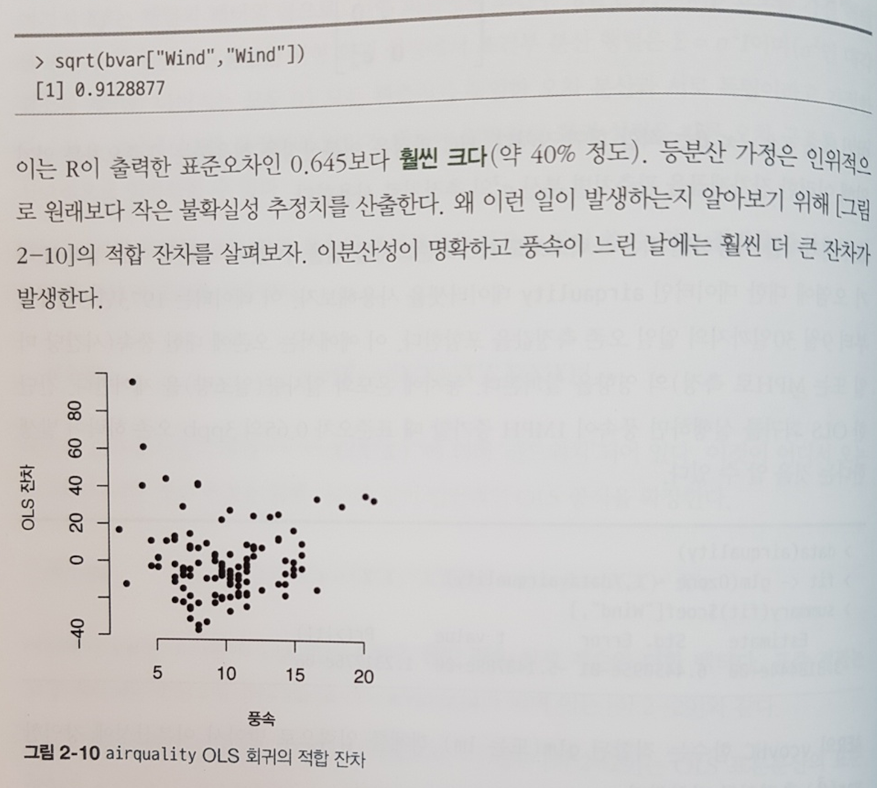
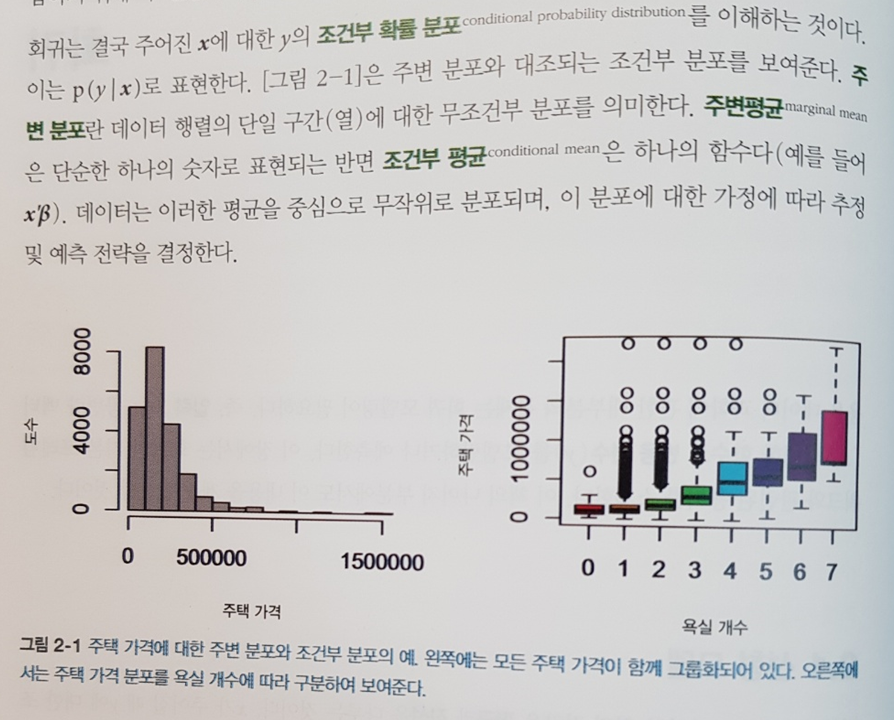
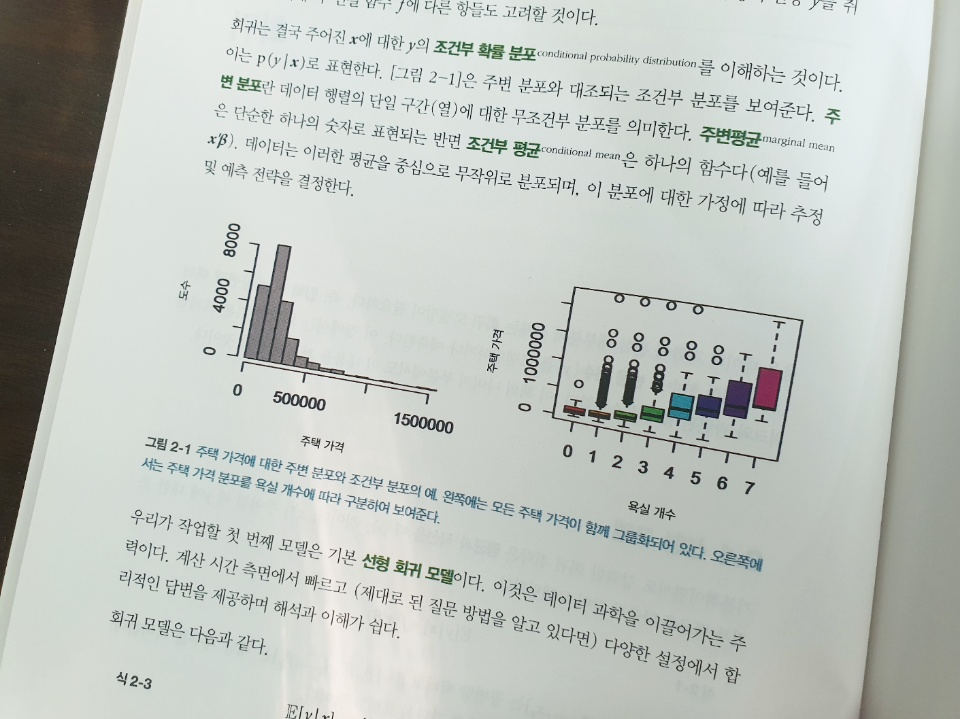
데이터를 분석해보고 그 알고리즘들을 하나씩 공부해보기도 하고 아래 그림처럼 시각적으로 표현하면 완전히 새로운 인사이트를 얻는 경우가 종종 있다. 책이 프로그래밍을 많은 비중을 다루고 있지는 않지만 충분히 많은 코딩 방법들도 익힐 수 있어서 다른 데이터를 응용해 볼 때도 많은 도움을 얻을 수 있다.

인공지능이나 머신러닝에 대한 것을 기대하고 이 책을 봤다면 조금 실망할지도 모르겠다. 챕터 10 이 되면 인공지능을 다루고 있긴 하지만 대부분 간단한 예와 용어에 대한 설명만으로 구성되어 있다. 40 페이지 정도의 아주 적은 양이라 인공지능에 대해 공부하는 책은 아니라고 봐야한다. 다만 이 책을 읽고 나면 다른 인공지능, 머신러닝 책들의 초반에 항상 나오는 기본적인 개념들이 상당히 쉽게 느껴지게 될 것이다. 쉬워서 기본서가 아니라 정말 그 학문들에 대한 기반이 담긴 책이다.

오랜만에 많은 시간을 두고 읽어보고 싶은 책을 받았다. 가만히 책처럼 읽어보고 하나씩 정리해가면서 봐야겠다. 2023년에는 나도 새로운 커리어를 만들 수 있지 않을까.
끝.
"한빛미디어 <나는 리뷰어다> 활동을 위해서 책을 제공받아 작성된 서평입니다."