![]() Eric Anderson
Eric Anderson
2019-05-08
![]() 16K
16K
더 많은 오픈 인터페이스와 메타프레임워크가 나오기를 기대하지만, 단점들이 있다.
딥러닝, 서버리스 함수, 그리고 스트림 처리와 같이 일반적으로 볼 수 있는 것들은 어떤 작업을 수행할까? 컴퓨팅내 큰 트렌드를 제외하고 이러한 움직인 뒤에는 오픈소스 프로젝트의 새롭고 독특한 방법이 구성되고 있다. 각 영역에서 여러 백앤드 중 하나를 사용해야 하는 API 전용 오픈 소스 인터페이스가 나타났다. 이러한 형태는 재작성을 줄이고, 쉽게 받아들이고 성능 향상을 하는등 업무에 많은 도움을 준다. 이러한 패턴에 대해 설명해보며, 어떻게 시작됐는지 설명하며, 오픈소스에서 이 패턴이 무엇을 의미하는지 자세히 알아본다.
일반적으로 새로운 오픈소스 프로젝트는 새로운 실행 기술과 사용자들이 프로그래밍할 수 있는 API를 제공한다. API 정의는 부분적으로 창의적인 활동으로 역사적으로 유추된 것(Storm의 스파우트(spout), 쿠버네티스의 포드(pod))을 통해 사용자들이 새로운 것을 어떻게 사용하는지 빠르게 이해할 수 있도록 도와준다. API는 프로젝트의 실행 엔진에서 기술되며, 하나의 독립형 형태로 만든다. 사용자는 프로젝트의 문서를 읽고 소프트웨어를 설치하고 인터페이스로 상호작용해 실행 엔진의 도움을 받는다.
몇몇 중요한 새로운 프로젝트는 다르게 구성됐다. 바로 실행 엔진을 가지고 있지 않다는 것이다. 대신, 여러 다른 실행 엔진에 공통적인 인터페이스를 제공하는 메타프레임워크이다. 두 번째로 인기있는 딥러닝 프레임워크인 케라스(Keras)가 이러한 형태이다. 프랑수아 콜렛(François Chollet)은 최근 “케라스는 엔드투엔드 프레임워크가 아니라 인터페이스로서 의미가 있다”고 설명했다. 마찬가지로, 대규모 데이터 처리 프레임워크인 Apache Beam도 “프로그래밍 모델”이다. 이것을 무엇을 의미할까? 프로그래밍 모델만으로 무엇을 할 수 있을까? 아무것도 하지 못한다. 이 두 프로젝트 모두 외부적인 백엔드가 필요하다. Beam의 경우 사용자는 6개의 오픈소스 시스템(Apache에서는 5개)과 3개의 개별 공급 시스템을 포함해 8개의 다른 “러너(runner)에서 실행할 수 있는 파이프라인을 작성한다. 마찬가지로 케라스는 텐서플로(Tensorflow), 마이크로소프트사의 인지 툴킷(CNTK), Theano, Apache MxNet등을 지원한다. 콜렛은 최근 Github에서의 변화로 이 접근에 대해 설명했다. “사실, 나아가 케라스의 멀티-백엔드 양상을 확장할 것이며.. .케라스는 텐서플로의 프론트엔드가 아닌 딥러닝에서의 프론트엔드가 될 것이다.”


이러한 유사점은 여기서 끝나지 않는다. Beam과 케라스는 원래 구글러(Googler)들이 동시에(2015년) 관련 분야(데이터 처리 및 기계 학습)에서 만들어졌다. 하지만 두 형태는 독립적으로 이 모델에 이른다. 어떻게 이런 일이 일어나고, 모델에게 무엇을 의미할까?
2015년, 필자는 구글의 클라우드 데이터 플로우 관련 일을 하는 프로덕트 매니저였다. 2004년 데이터 플로우 엔지니어링 팀의 전설적 지휘자였던 제프 딘(Jeff Deans)와 샌제이 게마왓(Sanjay Ghemawat)의 유명한 맵리듀스(MapReduce) 논문으로 거슬러 올라간다. 대부분의 프로젝트와 마찬가지로, 맵리듀스는 실행 방법과 이를 이용하기 위한 프로그래밍 모델을 정의했다. 실행 모델은 여전히 배치 처리를 위한 기술인 반면, 프로그래밍 모델은 업무에 적합지 않았다. 그래서 구글은 훨씬 쉽고 추상화된 프로그래밍 모델은 Flume(1단계, 그림 1)을 개발했다. 한편, 더 적은 지연 처리가 필요해 일반적인 실행 모델과 프로그래밍 모델인 MillWheel(2단계)프로젝트가 새로 등장했다. 흥미롭게도, 이 팀은 배치를 위한 추상화된 프로그래밍 모델인 Flume이 스트리밍을 위한 프로그래밍 모델이 될 수도 있다는 아이디를 가지고 있었다(3단계). 이러한 핵심적인 통찰력은 당시 데이터 플로우 모델인 Beam 프로그래밍 모델의 핵심이다.
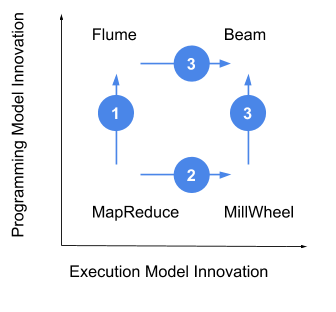
Beam의 탄생 스토리에서 다음과 같은 원리가 나타난다.
케라스의 경우 이 원칙을 따른다. 텐서플로의 인기에도 불구하고, 사용자들은 케라스의 API가 일반 용도가 아니라는 것을 깨달았다. Theano 사용자들 사이에서 많이 사용되는 케라스의 쉬운 추상화는 텐서플로에 선호되는 API로 만들었다. 이후 아마존과 마이크로소프트는 각각 MxNet과 CNKT를 백엔드로 추가했다. 이는 케라스가 독립적 개방형 인터페이스를 선택한 개발자들이 이제 코드를 다시 작성하지 않고 네 가지 주요 프레임워크를 모두 실행할 수 있다는 것을 의미한다. 이 조직들은 우수한 그룹으로부터 최신의 기술을 사용하고 있다. PlaidML과 같은 새로운 프로젝트는 많은 사람을 사로잡을 수 있다. 케라스 개발자는 새로운 인터페이스를 배우지 않고도 쉽게 PlaidML을 테스트할 수 있다.
서버리스(Serverless) 프레임워크의 개방향 인터페이스는 Beam과 같이 발전되었지만 명확하지는 않았다. 케라스와 Beam이 시작된 2015년 Hacker News에서 JAWS(Javascript AWS)의 발표를 본 기억이 난다. 몇 달 후 JAWS 팀은 Re:Invent에서 AWS 람다(Lambda)에 특화된 프레임워크를 발표했다. 아마존의 서비스로의 기능(function as a service,Faas)인 람다에 대한 워크플로우 및 모범 사례였다. 하지만 람다는 몇 가지 독점 클라우드 및 오픈 소스 Faas 제품 중 첫 번째 제품이었다. JAWS 프레임워크는 곧 서버리스로 재 탄생되었고 새로운 사람들에게 지원됐다.
오스틴 콜린스(Austen Collins)가 “서버리스 아키텍처의 누락”이라는 Event Gateway를 발표한 2017년 8월까지는 서버리스의 단일 개방형 API 인터페이스가 아니었다. 오늘날에도 서버리스는 자체 실행 환경을 제공하지 않는다. Gateway는 유명한 실행 환경을 추상화하고 사용할 수 있는 새로운 Faas API를 지정한다. Event Gateway에 대한 콜린스의 제안은 케라스나 Beam에서 가져왔을 수 있다.

벤처 투자자로서 회의적인 질문을 하고 있는 본인을 발견했다. 메타프레임워크가 진정한 현재 추세인가? 이러한 경향의 배경은 무엇일까? 왜 지금인가? 클라우드 관리 서비스와 혁신 속도라는 두 가지 이상의 힘이 작용하고 있다.
클라우드 관리 및 독점 서비스
사실상 모든 구글의 내부 관리 서비스는 구글 전용 API를 사용한다. 예컨대, 구글의 Bigtable은 최초의 noSQL 데이터베이스였다. 그러나 구글이 세부사항을 공개하는 것에 꺼려했기 때문에, 오픈소스 커뮤니티는 HBase, Cassandra등과 같은 자체 구현을 꿈꿨다. Bigtable을 외부 서비스로 제공한다는 것은 또 다른 API를 도입하는 것이므로, 또 하나의 독점적인 API를 시작하는 것을 의미한다. 대신, 구글 클라우드 Bigtable은 HBase 호환 API로 출시되었는데, 이는 HBase 사용자들이 코드 변경 없이 구글의 Bigtable 기술을 채택할 수 있다는 것을 의미한다. 개방형 인터페이스 이면에 독점 서비스를 제공하는 것은 구글 클라우드의 새로운 표준으로 보인다.
다른 클라우드 업체들도 이에 따른다. 마이크로소프트는 매회 오픈소스와 오픈인턴페이스를 받아들이지만, 아마존은 마지못해 고객들에 의해 섞여지고 있다. 두 업체는 최근 심층 학습 프레임워크에서 실행되는 개방형 API인 Gluon을 함께 출시했다. 클라우드 제공자들이 잘 채택된 개방형 API이면에 독점 서비스를 노출하는 추세는 락-인을 피하고 쉽게 채택할 수 있어 사용자에게 유리하다.
클라우드 제공이 증가하고 복잡함과 혁신 속도가 증가함에 따라, 더 많은 개방형 인터페이스와 메타프레임워크가 등장할 가능성이 있지만, 단점을 가지고 있다. 추상화 층을 추가하는 것은 부정적일 수 있다. 디버깅이 더 어려워질 수 있다. 기능이 지연되거나 지원이 안될 수도 있다. 인터페이스는 실행 엔진이 공유하는 접근 기능을 제공할 수 있지만, 값을 추가하는 거의 사용하지 않는 기능과 같은 정교한 부분은 생략한다. 마지막으로, 실행에 대한 새로운 접근방식은 기존 API에 즉시 맞지 않을 수 있다. 예컨대, PyTorch와 Kafka Streams는 최근 인기를 얻고 있으며, 아직 Keras와 Beam이 제공하는 개방향 인터페이스에는 준수하지 못하고 있다. 이는 사용자에게 어려운 선택을 줄뿐만 아니라 API 프레임워크의 개념에 도전한다.
지금까지를 고려했을 때, 새로운 세계에서 성공하기 위한 팁들을 살펴보자.
API 개발자 : API를 통해 개발한다면, (1)자체의 혁신 벡터라는 것과 (2)올바르게 하고자 업계 전체와 협력하는 것을 고려하자. 이는 오픈 소스의 지역사회와 거버넌스 측면에서 중요하다. 분산된 시스템에서 합의점을 얻는 것은 어렵지만, 프랑수아 콜레스 타일러 아키다우, 오스틴 콜린스는 각 영역에서 뛰어난 업적을 남겼다. 예컨대, 콜린스는 CNCF의 Serverless Working Group과 협력해 ClouldEvents를 업계 표준 프로토콜로 설정했다.
서비스 개발자 : 성능에 초점을 맞춰야한다. 개방형 인터페이스는 이제 분배 채널이 되어, 우수한 실행 프레임워크 생성에 집중할 수 있다. 더 이상 훌륭한 기술을 시도하거나 채택하기를 꺼려하는 게으름뱅이와 함께 있을 필요가 없다. 전환 비용 또한 적으므로, 개선 사항을 쉽게 알 수 있다. 벤치마킹이 표준이 되는 것을 살펴보자.
사용자 : 이러한 개방형 인터페이스의 커뮤니티를 활성해보자. API 사용 사례를 주도하고 관련성을 유지하고자 활발한 공간이 되어야 한다. 그리고 사용 가능한 다양한 백엔드를 이용해보자. 효율적으로 사용할 수 있으며, 성능과 혁신을 높일 수 있다.
모든 사람 : 이 기사에 언급된 프로젝트를 돕는 것을 고려해보자. 개방형 인터페이스는 여전히 새롭고, 개척자들의 성공에 미래는 달려 있다.
*****
원문 : Why your next open source project may only be an interface
번역 : 이창화
![]() 0
0




댓글