IT/모바일
제공 : 한빛 네트워크
저자 : Gilad Buzi, Kelley Glenn, Jonathan Novich
역자 : 백기선
원문 : Agile Database Refactoring with Hibernate
[이전 기사 보기]
하이버네이트를 사용한 애자일 데이터베이스 리팩토링(1)
POJO, 하이버네이트 맵핑, DAO
새로운 뷰 기반 데이터 모델을 위한 POJO와 하이버네이트 맵핑을 작성하는 것은 매우 간단합니다. 하지만 몇 가지 주의해야 할 것들이 있습니다.
가상 외래키와 주키
비록 데이터베이스 뷰는 외래키와 주키를 가지고 있지 않지만 맵핑 파일에는 정의해야 합니다. 이렇게 함으로써 다른 개발자들이 새로운 데이터 모델을 마치 실제 물리적인 모델처럼 생각할 것입니다. 더 나아가, 이런 요소들을 맵핑하는 것은 실제 테이블에 기반한 마지막 솔루션으로 이동할 때 거의 연관성이 없어 보이는 변화를 신뢰할 수 있게 해줍니다.
추가, 수정, 삭제 재정의하기
스토어드 프로시저를 사용할 때는 반드시 스토어드 프로시저를 호출하도록 추가, 수정, 삭제를 재정의해야 합니다. (instead of 트리거를 사용할 때 이렇게 할 필요가 없습니다.) 맵핑 파일에, , 엘리먼트를 사용하여 설정할 수 있습니다. 이 엘리먼트들은 데이터베이스에 직접 추가, 수정, 삭제를 하는 대신 하이버네이트가 호출할 프로시저를 알려줍니다. 다음에 ORDER_V 맵핑 정보가 나와있습니다.
데이터 접근 객체
제대로 된 맵핑이 자리를 잡으면, 뷰 기반 데이터 모델의 데이터 접근 객체는 테이블 기반 모델과 동일합니다. 하이버네이트가 스토어드 프로시저의 실행을 책임지고 뷰들을 테이블처럼 다루게 됩니다. 본 기사의 예제인 DMA 솔루션으로 완성된 ORDER_V와 ORDER_ITEM_V 뷰를 위한 데이터 접근 클래스를 참조하세요.
테스트, 테스트, 테스트
DMA 솔루션을 생성할 때 가장 중요한 것 중 하나가 전역적인(Extensive) 테스트 입니다. 오직 테스트를 통해서만 뷰 기반의 (논리적) 데이터 모델이 정확히 동작하는지 확인할 수 있습니다. 새로운 데이터 모델의 모든 측면이 테스트를 통해 확인되어야 합니다. 그리고 당연히 잘 작동하는 경우와 오동작하는 경우를 테스트 해봐야 할 것입니다.
DBUnit은 자동화 테스트를 훌륭히 도와줍니다. 비록 여기서는 DBUnit을 어떻게 사용할지 자세히 다루지는 못하지만(Andrew Glover가 작성한 이와 관련된 좋은 OnJava 기사가 있습니다.) 몇 가지 중요한 것들을 살펴보겠습니다.
평화로운 공존 정책
이제 애플리케이션이 정상적인 데이터 모델을 사용하도록 수정했습니다. 다른 애플리케이션들도 같은 데이터를 약간 다른 관점에서 접근할 수 있다는 것을 고려해야 합니다. 그렇다고 걱정할 필요는 없지만 그냥 그렇다는 것을 기억하고 있기만 하면 됩니다. [그림 3]은 새롭게 진보된 애플리케이션이 어떻게 기존의 애플리케이션과 평화롭게 공존하는지 보여줍니다.
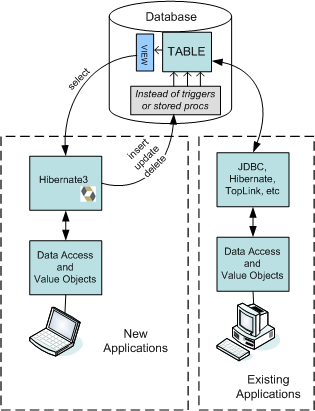
[그림 3] 기존 애플리케이션과 DMA 솔루션이 평화롭게 공존하고 있으며 같은 서로 다른 모델을 통해서 같은 데이터 셋을 사용하고 있습니다.
이제는 무엇을 해야 할까요? 기반이 되는 데이터 모델 이전하기
데이터모델을 수정하기 위해 멋진 해결책을 구현했습니다. 수 개월이 지나고 개발자들이 그들의 애플리케이션을 수정해 감으로써 점점 새로운 뷰 기반의 데이터 모델을 사용하기 시작했습니다. 하지만 그 기반이 되고 있던 역정규화 상태(또는 잘못 설계된)는 여전히 존재하고 있으며 그것을 제거하고 싶습니다. 하지만 어떻게 할까요? 여러분이 생각하는 것보다 실제는 더 간단합니 다. 다음에 단계별 가이드가 있습니다.
결론
최신의 그리고 훌륭한 하이버네이트의 기능과 자바 테스트 방법론 그리고 데이터베이스 자원을 잘 활용하면 점진적인 변화가 가능하다는 것을 보여드렸습니다. 데이터 모델의 문제를 이러한 방법으로 해결할 때 마법 같은 것은 이 해결책이 상호 배타적이라는 것입니다. 이 말은 여러분이 문제를 해결한 것을 (자신의 애플리케이션에서) 사용하더라도 같은 데이터를 사용하는 다른 애플리케이션들이 기존의 테이블을 사용하다가 여러분이 만든 개선된 것으로 옮기기 전까지 지속적으로 제대로 동작할 것 입니다. 친화적인 데이터 모델 마이그레이션 방법입니다.
마지막 요약으로 여러분의 솔루션을 구현할 때 다음의 몇 가지 사항들을 유념하시기 바랍니다.
* Gilad Buzi 는 10년 넘게 데이터 주도 애플리케이션 개발과 관련된 일을 하고 있습니다. 그는 현재 Code Works, Inc에서 선임 개발자(Principal Software Engineer)로 활동하고 있습니다.
* Kelley Glenn은 10년 넘게 소프트웨어 개발 산업에 종사하고 있으며 전화 요금과 엔터프라이즈 애플리케이션 통합의 경력을 가지고 있습니다.
* Jonathan Novich는 Code Works, Inc의 공동 설립자이자 파트너며 소프트웨어 컨설팅과 개발에 10년 넘게 종사하고 있습니다.
 역자 백기선님은 AJN(http://agilejava.net)에서 자바 관련 스터디를 하고 있는 착하고 조용하며 점잖은 대학생입니다.
요즘은 특히 Spring과 Hibernate 같은 오픈소스 프레임워크를 공부하고 있습니다. 공부한 내용들은 블로그(http://whiteship.tistory.com)에 간단하게 정리하고 있으며 장래 희망은 행복한 개발자입니다.
역자 백기선님은 AJN(http://agilejava.net)에서 자바 관련 스터디를 하고 있는 착하고 조용하며 점잖은 대학생입니다.
요즘은 특히 Spring과 Hibernate 같은 오픈소스 프레임워크를 공부하고 있습니다. 공부한 내용들은 블로그(http://whiteship.tistory.com)에 간단하게 정리하고 있으며 장래 희망은 행복한 개발자입니다.
저자 : Gilad Buzi, Kelley Glenn, Jonathan Novich
역자 : 백기선
원문 : Agile Database Refactoring with Hibernate
[이전 기사 보기]
하이버네이트를 사용한 애자일 데이터베이스 리팩토링(1)
POJO, 하이버네이트 맵핑, DAO
새로운 뷰 기반 데이터 모델을 위한 POJO와 하이버네이트 맵핑을 작성하는 것은 매우 간단합니다. 하지만 몇 가지 주의해야 할 것들이 있습니다.
가상 외래키와 주키
비록 데이터베이스 뷰는 외래키와 주키를 가지고 있지 않지만 맵핑 파일에는 정의해야 합니다. 이렇게 함으로써 다른 개발자들이 새로운 데이터 모델을 마치 실제 물리적인 모델처럼 생각할 것입니다. 더 나아가, 이런 요소들을 맵핑하는 것은 실제 테이블에 기반한 마지막 솔루션으로 이동할 때 거의 연관성이 없어 보이는 변화를 신뢰할 수 있게 해줍니다.
추가, 수정, 삭제 재정의하기
스토어드 프로시저를 사용할 때는 반드시 스토어드 프로시저를 호출하도록 추가, 수정, 삭제를 재정의해야 합니다. (instead of 트리거를 사용할 때 이렇게 할 필요가 없습니다.) 맵핑 파일에
이때 파리미터의 순서가 중요합니다. 하이버네이트 매뉴얼 중 custom SQL reference 부분을 참조하여 스토어드 프로시저의 파라미터 순서를 정하시기 바랍니다.{call insert_order(?, ?, ?)} {call update_order(?, ?, ?)} {call delete_order(?)}
데이터 접근 객체
제대로 된 맵핑이 자리를 잡으면, 뷰 기반 데이터 모델의 데이터 접근 객체는 테이블 기반 모델과 동일합니다. 하이버네이트가 스토어드 프로시저의 실행을 책임지고 뷰들을 테이블처럼 다루게 됩니다. 본 기사의 예제인 DMA 솔루션으로 완성된 ORDER_V와 ORDER_ITEM_V 뷰를 위한 데이터 접근 클래스를 참조하세요.
테스트, 테스트, 테스트
DMA 솔루션을 생성할 때 가장 중요한 것 중 하나가 전역적인(Extensive) 테스트 입니다. 오직 테스트를 통해서만 뷰 기반의 (논리적) 데이터 모델이 정확히 동작하는지 확인할 수 있습니다. 새로운 데이터 모델의 모든 측면이 테스트를 통해 확인되어야 합니다. 그리고 당연히 잘 작동하는 경우와 오동작하는 경우를 테스트 해봐야 할 것입니다.
DBUnit은 자동화 테스트를 훌륭히 도와줍니다. 비록 여기서는 DBUnit을 어떻게 사용할지 자세히 다루지는 못하지만(Andrew Glover가 작성한 이와 관련된 좋은 OnJava 기사가 있습니다.) 몇 가지 중요한 것들을 살펴보겠습니다.
- 데이터 다양성(Data diversity) 테스트 데이터가 확실히 (외래키 관계와 빈(null) 값과 같은)모든 종류의 데이터 시나리오를 반영하고 있는지 확인합니다.
- 데이터셋 규모(Dataset size) 물론 여러분의 모든 테스트를 지원하기 위한 상당히 많은 데이터를 유지하는 것은 중요하지만 DBUnit을 사용하여 모든 테스트 메소드 마다 데이터를 지우고 다시 읽어 들일 수 있다는 것을 기억하시기 바랍니다. 상당히 많은 데이터는 테스트를 느리게 만듭니다.
- Find All DAO가 예상한 만큼의 row의 개수를 반환하는지 확인
- Find one 가상 주키를 사용하여 레코드를 가져오고 가져온 레코드의 모든 값(컬럼)들이 예상한 값들과 같은지 확인
- Insert 레코드 하나를 추가하고 추가 되었는지 확인
- Insert multiple records 한 번에 하나 이상의 레코드를 추가하는 것이 제대로 동작하는지 확인
- Insert duplicates 가상 주키의 제약 사항을 어기는 것을 시도
- Delete 레코드를 삭제해보고 진짜로 제거 되었는지 확인
- Delete multiples 여러분이 설계한 DAO가 이 기능을 지원할 때 해보세요.
- Update 수정을 하고 DB에 수정된 내용이 영속화 되었는지 확인
- Violate constraints 모든 가능한 가상 제약들을 테스트했는지 확인
- Optimistic locking 낙관적인 롹킹 예외(optimistic locking)를 발생할 수 있는 몇 가지 방법들이 있습니다. 낙관적인 롹킹 예외가 제대로 동작하는지 확인하려면 다음의 네 가지 조건을 확인해봐야 합니다.
- 이미 삭제한 레코드를 삭제하려고 할 때
- 최근 팻치(fetch)로 수정된 레코드를 삭제하려고 할 때(이 것은 버전 컬럼을 사용할 때 가능합니다.)
- 삭제된 레코드를 수정하려고 할 때
- 최근 팻치(fetch)로 삭제된 레코드를 수정하려고 할 때(이 것은 버전 컬럼을 사용할 때 가능합니다.)
평화로운 공존 정책
이제 애플리케이션이 정상적인 데이터 모델을 사용하도록 수정했습니다. 다른 애플리케이션들도 같은 데이터를 약간 다른 관점에서 접근할 수 있다는 것을 고려해야 합니다. 그렇다고 걱정할 필요는 없지만 그냥 그렇다는 것을 기억하고 있기만 하면 됩니다. [그림 3]은 새롭게 진보된 애플리케이션이 어떻게 기존의 애플리케이션과 평화롭게 공존하는지 보여줍니다.
[그림 3] 기존 애플리케이션과 DMA 솔루션이 평화롭게 공존하고 있으며 같은 서로 다른 모델을 통해서 같은 데이터 셋을 사용하고 있습니다.
이제는 무엇을 해야 할까요? 기반이 되는 데이터 모델 이전하기
데이터모델을 수정하기 위해 멋진 해결책을 구현했습니다. 수 개월이 지나고 개발자들이 그들의 애플리케이션을 수정해 감으로써 점점 새로운 뷰 기반의 데이터 모델을 사용하기 시작했습니다. 하지만 그 기반이 되고 있던 역정규화 상태(또는 잘못 설계된)는 여전히 존재하고 있으며 그것을 제거하고 싶습니다. 하지만 어떻게 할까요? 여러분이 생각하는 것보다 실제는 더 간단합니 다. 다음에 단계별 가이드가 있습니다.
- Develop tables: These will look much like your views, but will have real foreign keys and indexes. Make sure to maintain the same column names as the views themselves.
- 테이블 만들기 : 뷰와 상당히 비슷하게 만들어지겠지만 진짜 외래키와 인덱스를 가지고 있습니다. 뷰와 같은 컬럼 이름을 사용하는지 확인하기 바랍니다.
- Load tables: You will load the tables with data from your already existing views. Select from view into table. It"s really that simple.
- 테이블 로딩하기 : 기존의 뷰에 이미 존재하는 데이터를 가지고 테이블을 로딩합니다. 뷰에서 테이블로 선택을 변경 합니다. 실제로 간단합니다.
- 맵핑 파일 수정하기 : 하이버네이트 맵핑을 변경하여 뷰 대신에 테이블을 사용하고, 만약 스토어드 프로시저를 사용한다면
, 와 엘리먼트르르 제거합니다.(더 이상 필요 없기 때문이죠.) - 테스트, 테스트, 테스트 : 기존의 테스트들은 절대로 수정할 필요가 없습니다. 그것들을 계속하여 다시 실행하면서 검증하면 됩니다.
결론
최신의 그리고 훌륭한 하이버네이트의 기능과 자바 테스트 방법론 그리고 데이터베이스 자원을 잘 활용하면 점진적인 변화가 가능하다는 것을 보여드렸습니다. 데이터 모델의 문제를 이러한 방법으로 해결할 때 마법 같은 것은 이 해결책이 상호 배타적이라는 것입니다. 이 말은 여러분이 문제를 해결한 것을 (자신의 애플리케이션에서) 사용하더라도 같은 데이터를 사용하는 다른 애플리케이션들이 기존의 테이블을 사용하다가 여러분이 만든 개선된 것으로 옮기기 전까지 지속적으로 제대로 동작할 것 입니다. 친화적인 데이터 모델 마이그레이션 방법입니다.
마지막 요약으로 여러분의 솔루션을 구현할 때 다음의 몇 가지 사항들을 유념하시기 바랍니다.
- 제로 임팩트(Zero impact) DMA 솔루션은 기존의 애플리케이션이나 프로세스에 영향을 주면 안됩니다. 이 말은 새로운 (가상) 데이터 모델이 변경 되면 실제 (결함이 있는 데이터 모델의) 데이터도 변경되어야 한다는 것입니다.
- 기능성 유지 새로운 데이터 모델이 특정 컬럼의 중요성을 제거 하더라도 지속적으로 예전의 행위를 유지할 수 있어야 하는 것이 중요합니다. 계산되는 필드가 이에 가장 적합한 예입니다. 만약에 기존 애플리케이션이 추가하기 전에 계산을 하지만 새로운 모델은 심지어 해당 필드를 가지고 있지 않다면 DMA 솔루션은 기존의 행위를 보장해야 하며 필드를 계산해야 합니다. (그리고 추가도 해야겠죠.)
- 완벽한 자신감을 위한 테스트 DMA 솔루션은 충분히 테스트해야 새로운 스키마가 기존의 데이터베이스 스키마만큼 튼튼하다는 자신감을 가질 수 있습니다. DMA 패턴은 단순하게 테이블과 컬럼을 맵핑하는 것이 아니기 때문에 버그가 생기기 쉽습니다. 시도를 한 다음 테스트를 토해서 솔루션이 제대로 됐으며 완벽한 ACID 원칙들을 보장하는지 확인할 수 있습니다.
- 이 기사를 위한 예제 코드
- 하이버네이트에 대해 좀 더 자세한 정보
- MySQL에서 스토어드 프로시저를 작성하는 가이드를 제공하는 MySQL 문서
* Gilad Buzi 는 10년 넘게 데이터 주도 애플리케이션 개발과 관련된 일을 하고 있습니다. 그는 현재 Code Works, Inc에서 선임 개발자(Principal Software Engineer)로 활동하고 있습니다.
* Kelley Glenn은 10년 넘게 소프트웨어 개발 산업에 종사하고 있으며 전화 요금과 엔터프라이즈 애플리케이션 통합의 경력을 가지고 있습니다.
* Jonathan Novich는 Code Works, Inc의 공동 설립자이자 파트너며 소프트웨어 컨설팅과 개발에 10년 넘게 종사하고 있습니다.
역자 백기선님은 AJN(http://agilejava.net)에서 자바 관련 스터디를 하고 있는 착하고 조용하며 점잖은 대학생입니다.
요즘은 특히 Spring과 Hibernate 같은 오픈소스 프레임워크를 공부하고 있습니다. 공부한 내용들은 블로그(http://whiteship.tistory.com)에 간단하게 정리하고 있으며 장래 희망은 행복한 개발자입니다. TAG :
이전 글 : 하이버네이트를 사용한 애자일 데이터베이스 리팩토링(1)
다음 글 : 리눅스에서의 세마포어(1)

최신 콘텐츠